What is Synthetic Data?
Synthetic data is artificially generated data that mimics real-world datasets without exposing sensitive information. This article explains how synthetic data is created, its benefits, use cases, and why it’s critical for privacy-safe AI training.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
Artificially generated data by generative AI models is synthetic data. It is not real-world data.
How is it Generated?
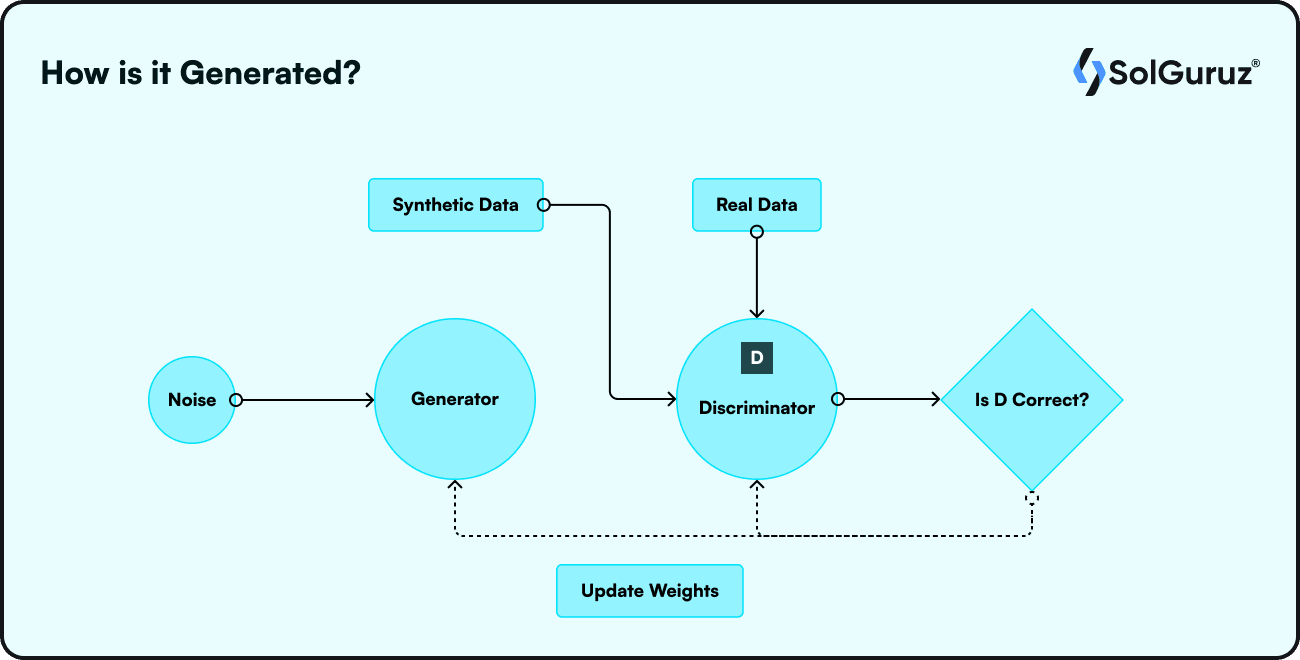
Synthetic data generation is the process of creating new data, either automatically using computer simulations or algorithms.
Alternatively, this fake data can be built from an existing data set. The newly created data and the original data are almost exactly the same. Any size, at any time, and anywhere can produce synthetic data.
Data augmentation is one area of generative AI where synthetic data is crucial. The diverse dataset provided by this technique helps generalize the AI model.
Why is it Required?
The requirement for these assets stems from a few factors –
Data Availability
Initially, it can come down to availability. There isn't enough or the right kind of data in your team or business. Data unavailability is frequently caused by aging infrastructures and siloed data systems in larger enterprises.
Regulatory Compliance
It may also be a question of legal compliance in the current regulatory environment around data protection. There is data, but processing it is very tightly controlled. For example, the General Data Protection Regulation (GDPR) prohibits uses for which consent was not obtained explicitly at the time the data was collected by the organization. To navigate these complex requirements effectively, a can help ensure compliance, reduce legal risks, and guide proper data handling practices.
Security Concerns
Data flow within a company may also be impeded by security concerns. For example, the data cannot be moved to a cloud infrastructure because it is too sensitive. Additionally, governance procedures may become more sluggish.
Some major security concerns exist when we are talking about personally identifiable information(PII). Organizations protect such sensitive details, so such information is not disclosed when data is collected. This scenario creates the need for synthetic data generation. While having security concerns the first question ringing in the mind is – “Can we trust this synthetically generated data?”
Cost
Cost-effectiveness is another area that impacts data generation in AI. Developing and producing data from generative AI models is too costly. Simply because the cost to create new data samples involves the addition of new neural networks and sample collection. And neural networks, we know, are very expensive.
Synthetic data generation saves money by generating data on training real-world samples. It reduces the cost of sample collection.
The following postulates answer the question, “Why is synthetic data required?” While discussing the advantages of synthetic data, the above-mentioned issues become more clear.
Characteristics of Synthetic Data
The various characteristics exhibited by synthetic data -
Enhanced data quality
Acquiring real-world data can be challenging and costly, and it may also be subject to biases, errors made by humans, and inaccuracies. These factors can all negatively affect the caliber of a machine-learning model. However, while creating synthetic data, businesses can have more faith in the information's accuracy, balance, and diversity.
Scalability of data
Data scientists are forced to use synthetic data due to the rising need for training data. Its size can be changed to meet the machine learning models' requirements for training.
Easy to use and efficient
Using algorithms makes it very easy to create phony data. However, it's crucial to make sure that the artificial data is error-free, free of additional biases, and does not show any connections to the real data.
Advantages of Synthetic Data
Synthetic data is generated by generative AI models. It is beneficial in many industries. Here are some benefits of synthetic data –
- Customizable: Synthetic data can be produced to satisfy a business's unique requirements.
- Cost-effective: When compared to genuine data, synthetic data is a more economical solution. For example, it will cost an automobile manufacturer more to collect actual vehicle collision data than to develop synthetic data.
- Faster to produce: With the right hardware and tools, a dataset can be created and assembled considerably more quickly than one that is based on real-world occurrences because synthetic data is not gathered from them. This implies that a vast amount of synthetic data can be made available more quickly.
- Preserves data privacy: Synthetic data should ideally not contain any identifiable information about the original data but rather simply mimic real data. Because of this feature, the synthetic data is anonymous and suitable for distribution.
Types of Synthetic Data
It is crucial to understand the kind of synthetic data needed to address a business issue before selecting the best synthetic data creation technique. The types of synthetic data are fully synthetic and partially synthetic.
Fully Synthetic data is unrelated to actual or real-world data. This shows that although all the necessary variables are present, the data cannot be identified.
All of the original data is retained as partially synthetic data, with the exception of sensitive data. Since it is taken out of the real data, there is a chance that the true values will occasionally still be present in the carefully chosen artificial data set.
The different varieties of synthetic data can be –
- Text
- Media
- Tabular Data
1. Synthetic Text
Text created artificially is known as synthetic text. A model is constructed and trained to generate text. It has never been easy to create realistic-looking synthetic writing because of the complexity of languages. On the other hand, the development of novel machine-learning models gave birth to the creation of extraordinarily effective natural language generation systems.
The GPT-3 technique is a type of neural network that was trained on an enormous volume of text and belongs to a deep learning class known as large language models. Although the most well-known and accessible large language model is GPT-3, DeepMind, Google, and Meta have all created their own in recent years.
2. Synthetic Media
Synthetic Media includes images, audio, and videos. Media can be artificially rendered with qualities that approximate real-world data. Because of these similarities, the synthetic media can be used in place of the original data without any issues.
To create realistic renderings of human faces, the algorithm acquired characteristics from photos of actual people.
This technique can expand the databases used to train machine learning algorithms. Synthetic data comes in handy when generating synthetic videos. Many times, video data is unavailable for training purposes due to privacy concerns. Synthetic tools help generate synthetic videos here. Similar to this, while training image recognition systems, you can use synthetic data to expand the quantity and diversity of datasets.
Various concepts of AI, like diffusion models, data augmentation, and many others, have been implemented using synthetic data.
3. Synthetic Tabular Data
Artificially created data that is stored in tables and resembles real-world data is referred to as tabular synthetic data. This data structure has rows and columns. It could be anything, such as money logs, user analytical activity data, or patient databases.
Today's business intelligence and data science endeavors revolve around data. As was previously indicated, there are certain situations in the business where real-world data cannot flow between subsidiaries, partners, or divisions.
Use Cases of Synthetic Data
The implementation of synthetic data finds its use in different concepts like data augmentation, diffusion models, and many others. Various industries and technologies -
Natural Language Processing
Natural language processing is one subject where synthetic data is useful. The artificial intelligence team of Amazon Alexa utilizes synthetic data to finish the training set for its natural language understanding (NLU) system. It provides them with a strong foundation to train additional languages in the event that there is insufficient or no existing customer interaction data.
Data Security
A health insurance provider is collaborating with Google Cloud to create a platform for synthetic data. Using statistical models and algorithms, the platform will produce 1.5–2 petabytes of synthetic data, including medical records, insurance claims, and artificial intelligence-generated medical histories. The ultimate objective is to minimize privacy problems while validating and training AI systems with vast amounts of personal health data.
Healthcare
Synthetic data is used by healthcare organizations to build models and test a range of datasets for illnesses for which there is a lack of real data. Artificial intelligence (AI) models in medical imaging are trained with fake data while maintaining patient privacy. They also use artificial intelligence (AI) to foresee and predict disease patterns.
Banking Finance
The banking sector uses synthetic data to identify and prevent financial fraud through predictive analysis. Companies like J.P. Morgan carry out research and build algorithms to provide realistic synthetic datasets to expedite the development of financial AI research.
Closing Thoughts
Actual real-world data will always be favored when making business decisions. However, synthetic data is a good substitute when real raw data of this kind is not available for analysis. However, it should be kept in mind that data scientists with a strong understanding of data modeling are required to create synthetic data. It's also essential to have a thorough comprehension of the actual data and its surroundings.
FAQs
1. What is synthetic data in simple terms?
Synthetic data is artificially created data generated by AI models or simulations instead of being collected from real-world events. It is designed to behave like real data while helping businesses protect privacy and improve machine learning training.
2. Why is synthetic data important in generative AI?
Synthetic data helps train AI models when real data is limited, sensitive, expensive, or difficult to collect. It improves model performance, supports faster development, and helps businesses meet data privacy and compliance requirements.
3. What are the main types of synthetic data?
The two main types are fully synthetic data and partially synthetic data. Fully synthetic data is completely generated and has no direct link to real data, while partially synthetic data keeps some original data and replaces only sensitive information.
4. Where is synthetic data commonly used?
Synthetic data is widely used in healthcare, banking, finance, data security, natural language processing, computer vision, and machine learning. It helps organizations train AI systems without exposing private or sensitive information.
5. What is the difference between synthetic data and data augmentation?
Synthetic data creates entirely new artificial data using AI models or simulations, while data augmentation modifies existing data by making small changes like rotation, cropping, or text variation. Both improve AI training but serve different purposes.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
From Our Portfolio
AI Projects We Have Shipped to Production
SolGuruz has shipped 102+ products across 14 industries. See how SolGuruz built production AI applications - LLM-powered clinical documentation, AI travel planning, healthcare staffing intelligence, and AI journaling - using GPT-4, Claude, and custom ML models at real-world scale.

AI Clinical Notes Platform That Turns 2-Hour Documentation Into One Click
NoteCliniq transforms clinical conversations into HIPAA-compliant SOAP notes in seconds, eliminating 2+ hours of manual documentation daily for busy clinicians.
Key Outcomes
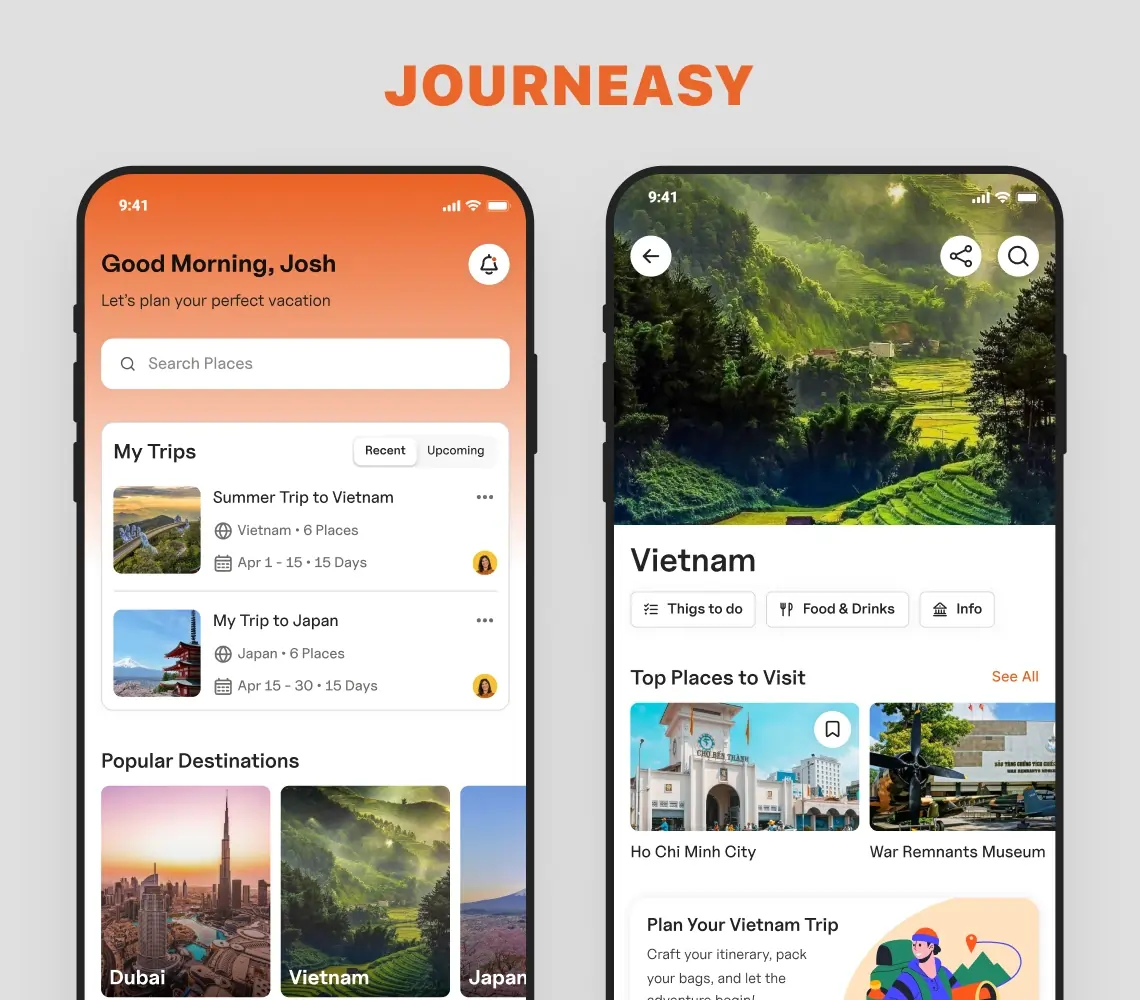
AI-Powered Trip Planner App Solution
Explore how SolGuruz created an AI-powered trip planner app. It is an exclusive AI vacation planner that helps with finding hotels, cabs, places, and complete itineraries.
Key Outcomes
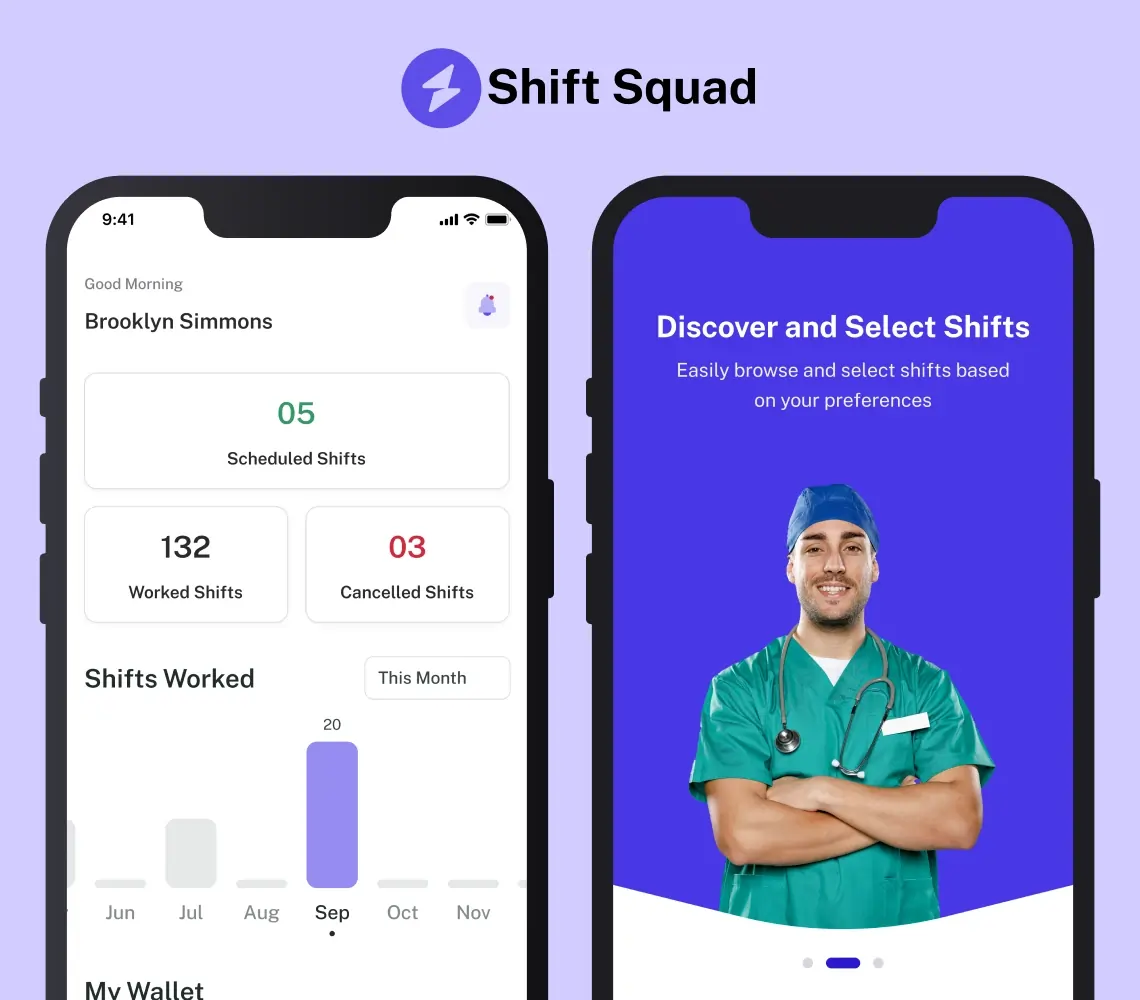
AI-Powered Healthcare Staffing App Solution
Explore our AI-powered healthcare staffing app case study. See how SolGuruz’s expertise transforms nurse staffing challenges into seamless solutions.
Key Outcomes

AI Journaling App Development Solution
Discover with us how we built Dream Story, an AI-powered journaling application that helps manage daily notes by capturing your thoughts and emotions. A one-stop solution for those who love noting down daily summaries!
Key Outcomes
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

