Giraffe Eating Buildings and Diffusion Models
Diffusion models generate high-quality images and data by learning to reverse noise processes. This guide explains how diffusion models work, why they outperform older approaches, and where they’re used in modern generative AI systems.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
The rising era of AI-generated art and diffusion models go hand in hand. We have never seen a giraffe eat a building or, for that matter, a giraffe in urban areas. But technology has made our wildest imagination possible. You write a text in the prompt bar of the diffusion model (DALL-E, Stable Diffusion, or others), and they can give you the wildest of images. This new image-generation technique can do wonders. Here’s one for your curiosity -
What are Diffusion Models?
“Diffusion” is a thermodynamic term that refers to the movement of molecules from higher to lower concentrations.
In AI, since the term is derived from thermodynamics, it is a phenomenon that reverses the process of gradually adding noise to a dataset to produce unique, high-quality data.
Owing to this novel technique, they can produce remarkably accurate and detailed outputs, ranging from coherent text sequences to lifelike visuals. The idea of gradually deteriorating data quality and then reconstructing it in its original form or transforming it into something new is fundamental to how they work. This method offers new opportunities in fields like medical imaging, driverless cars, and tailored AI helpers while also improving the quality of created data.
How Do They Work?
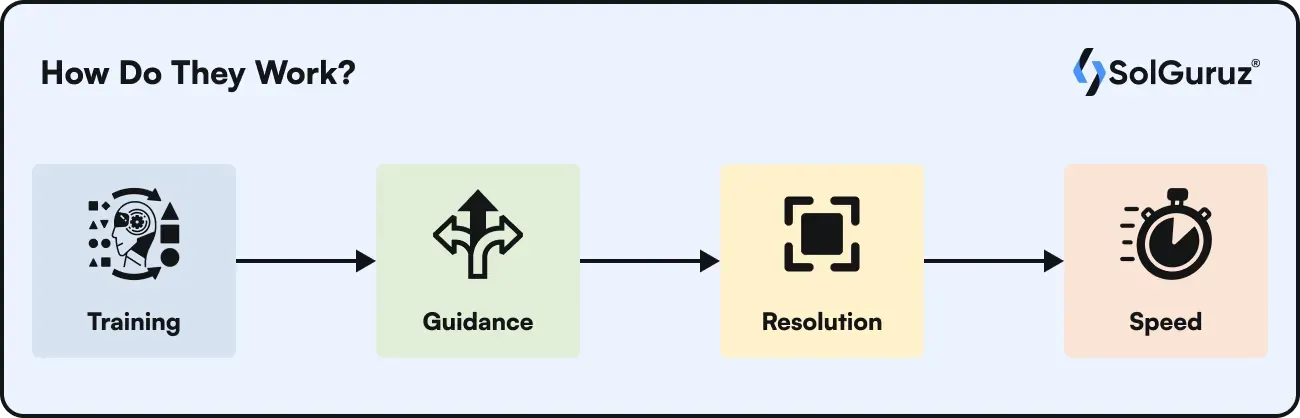
While understanding how diffusion works, we must understand that diffusion models work on
- Training
- Guidance
- Resolution
- Speed
Before going further, let's understand one thing-
AI models learn and train on the data they are fed. They train to generalize the data and learn the patterns. On the basis of the learnings, they predict the outcomes. So,
the outcome depends on the data.
Simple explanation -
Diffusion models work by first introducing noise to erase training data, then learning to reverse this noise to recover the data. Put differently, diffusion models can generate meaningful visuals from random data.
The basic concept of the diffusion model has these components -
Forward Process - Addition of noise in the training data
The forward diffusion process starts with a fundamental distribution, Gaussian distribution, to be sampled. This first simple sample is subjected to a sequence of reversible incremental alterations, where a Markov chain is used to introduce a regulated amount of complexity at each stage. It adds complexity piece by piece, which is frequently represented as the addition of organized noise. The model is able to capture and replicate the intricate patterns and nuances present in the target distribution because of the diffusion of the original data through subsequent changes.
Simply speaking, in the forward process, a small Gaussian noise is incrementally added to the data over a few steps. After the noise is added to the distribution, the result is a series of increasingly noisy samples.
Reverse Process - Removal of noise from the training data
The neural network is trained to denoise the incrementally noisy data generated in the forward diffusion process. This is in accordance with the unique noise patterns that are added at each step in the reverse diffusion process. This is not a straightforward procedure; rather, a Markov chain is used to perform intricate reconstruction. At each step, the model predicts the noise using the knowledge it has learned, and then it carefully eliminates it.
Diffusion models learn how to remove noise by adding noise to images during training. To produce realistic images, the model then applies the denoising technique to random seeds.
The obvious question is: Why Does the Model Have to Add Noise to the Data?
The model is fed with real-world data, which contains some noise; it is not ideal data. Synthetic data is created noise-free and works as ideal data.
When the model is fed with synthetic data, i.e., noise-free data, it learns the patterns of this data and gives predictions based on the data. Now, when real-world data is fed to the model, the predictions will not be as accurate as when the model is trained on synthetic noise-free data.
Hence, adding noise to the data generalizes the model to read the patterns with noise and learn to make predictions with real-world data. Now, these predictions are nearly accurate.
Difference between Diffusion Models and Diffusion Transformers
Diffusion models and diffusion transformers are the concepts of AI and machine learning.
Diffusion Transformers
A class of diffusion models based on the transformer design is called Diffusion Transformers (DiT). DiT seeks to enhance the performance of diffusion models by substituting a transformer for the widely used U-Net backbone. Open AI’s SORA and Stable Diffusion 3 are prominent examples of tools using diffusion transformers.
Diffusion Models
Diffusion models are a type of generative models that are used in noising and denoising the training data to create noise-free accurate data. The forward and reverse process creates noise-free data. U-Net architectures are used in the processing of diffusion models to give better and more accurate predictions.
Use Cases
Diffusion models have many different uses, but one of the most fascinating is in the production of digital art. With the aid of these models, artists can create intricate, visually arresting visuals from abstract ideas or written descriptions. This power enables artists to explore new forms and concepts that were previously difficult or impossible to execute, leading to a new kind of artistic expression where the lines between technology and art are blurred. The use of generative AI and prompts is needed to perfect the diffusion models. Some popular use cases include
Film and Animation
Diffusion models may provide dynamic aspects in scenes, realistic backgrounds, and characters, saving time and effort compared to standard production methods. As a result, the workflow is streamlined, and more experimentation and innovation in visual storytelling are possible.
Music
In sound design and music, generative diffusion models can be modified to produce original soundscapes or to depict music, providing new avenues for artists to imagine and produce aural works.
Neuroscience
In neuroscience, diffusion models are used to study brain activity, cognitive processes, and decision-making. They allow us to forecast neurological or behavioral patterns, model cognitive operations, and comprehend mechanisms.
Biological Field- Cancer Detection
In the future, diffusion models will be used in the detection of cancerous cells. Diffusion models may be used in this sector in the future, possibly to simulate the spread of substances produced by radiation inside cells.
Another application is that it recognizes and creates ideal protein sequences with particular characteristics. It can also be applied to biological data imaging, including morphological profiling and high-resolution cell microscopy.
Final Thoughts
Diffusion models have genuinely changed the way we see AI's capacity to produce audio, visuals, and video. These models work by first adding noise to the data and then deftly taking it out, which enables them to produce intricate and superior patterns.
Diffusion models are advancing more than just creativity in art and design; they are also helping to advance autonomous vehicles and medical imaging. Their adaptability provides an intriguing window into the continuous development and burgeoning potential of AI.
FAQs
1. What is a diffusion model in AI?
A diffusion model is a type of generative AI that creates new images, videos, or audio by learning how to turn random noise into clear, useful content. It first studies how clean data becomes noisy, then learns how to reverse that process. Once trained, it can create brand-new outputs from pure noise.
2. How do diffusion models work?
Diffusion models work in two simple steps. First, small amounts of random noise are added to training data until the data becomes completely noisy. Then, a neural network learns to remove that noise step by step. To create a new output, the model starts with random noise and slowly cleans it up until a realistic image, video, or sound appears.
3. What is the forward process in a diffusion model?
The forward process is where the model slowly adds noise to clean training data. A little bit of noise is added at each step until the data is fully turned into random noise. This gives the model many examples of how clean data breaks down, which helps it learn how to rebuild data later.
4. What is the reverse process in a diffusion model?
The reverse process is how a diffusion model creates new content. Starting with pure random noise, the trained neural network removes a small amount of noise at each step. After many steps, the noise becomes a clear image, video frame, or audio clip. This is the step that actually generates the final output.
5. Why do diffusion models add noise to data during training?
Adding noise helps the model learn how real-world data looks when it is imperfect. Real data is rarely clean, so training only on perfect data would make the model weak in real situations. By practicing on many levels of noisy data, the model learns to create sharper, more realistic outputs when generating something new.
6. What is the difference between a diffusion model and a diffusion transformer?
A diffusion model is the general method of adding and removing noise to generate data. A diffusion transformer (DiT) is a newer version that uses a transformer architecture instead of the common U-Net design. Diffusion transformers scale better and produce higher-quality results. OpenAI's Sora and Stable Diffusion 3 are popular examples of diffusion transformers.
7. What is the difference between diffusion models and GANs?
Diffusion models create content by slowly removing noise, while GANs (Generative Adversarial Networks) use two neural networks that train against each other a generator and a discriminator. Diffusion models usually produce better image quality and are easier to train. GANs are often faster but harder to train reliably and can miss certain types of outputs.
8. What are popular examples of diffusion models?
Popular diffusion models include Stable Diffusion, DALL·E, Midjourney, and Google Imagen for image generation, and OpenAI's Sora for video generation. These tools are widely used for text-to-image creation, digital art, animation, marketing visuals, and short-form video content.
9. What are the common applications of diffusion models?
Diffusion models are used for AI image generation, video generation, digital art, animation, film production, music and sound design, medical imaging, protein structure research, and scientific simulation. Any field that needs realistic synthetic visuals, audio, or structured data can benefit from diffusion models.
10. What are the main limitations of diffusion models in 2026?
Diffusion models are powerful but come with trade-offs. They are slower to generate outputs because they rely on multiple denoising steps, require large training datasets, and demand high GPU and memory resources. In 2026, research is improving efficiency, but performance and cost remain key challenges.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
From Our Portfolio
AI Projects We Have Shipped to Production
SolGuruz has shipped 102+ products across 14 industries. See how SolGuruz built production AI applications - LLM-powered clinical documentation, AI travel planning, healthcare staffing intelligence, and AI journaling - using GPT-4, Claude, and custom ML models at real-world scale.

AI Clinical Notes Platform That Turns 2-Hour Documentation Into One Click
NoteCliniq transforms clinical conversations into HIPAA-compliant SOAP notes in seconds, eliminating 2+ hours of manual documentation daily for busy clinicians.
Key Outcomes
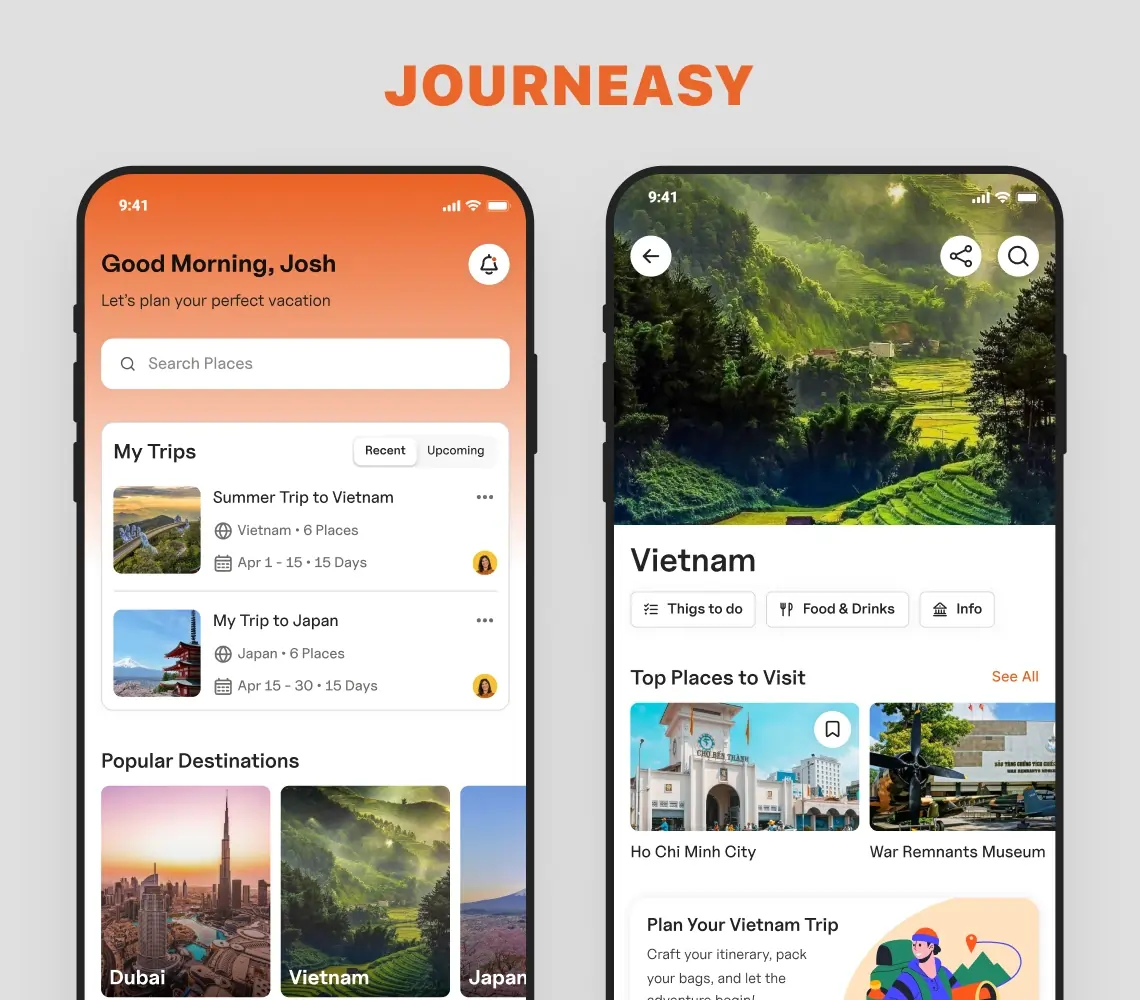
AI-Powered Trip Planner App Solution
Explore how SolGuruz created an AI-powered trip planner app. It is an exclusive AI vacation planner that helps with finding hotels, cabs, places, and complete itineraries.
Key Outcomes
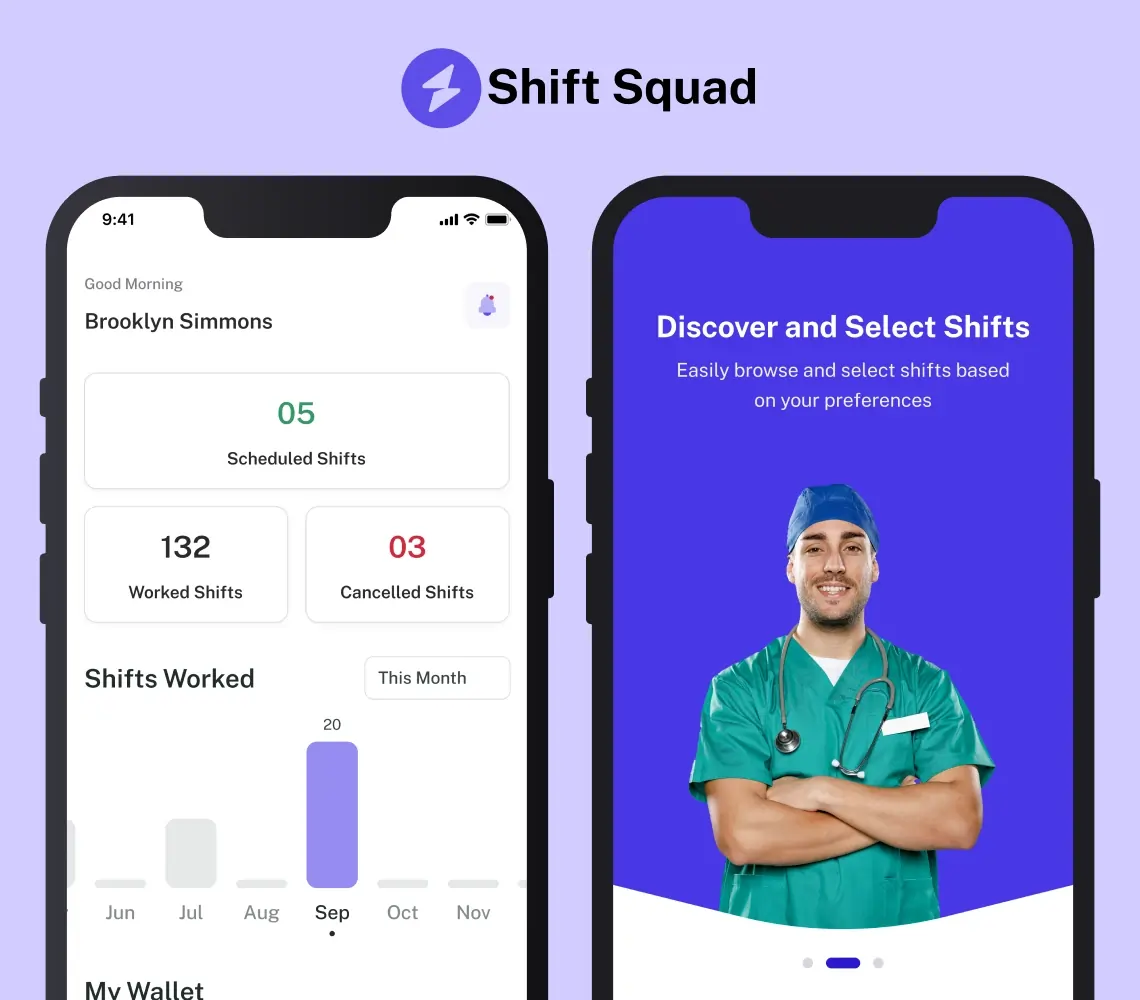
AI-Powered Healthcare Staffing App Solution
Explore our AI-powered healthcare staffing app case study. See how SolGuruz’s expertise transforms nurse staffing challenges into seamless solutions.
Key Outcomes

AI Journaling App Development Solution
Discover with us how we built Dream Story, an AI-powered journaling application that helps manage daily notes by capturing your thoughts and emotions. A one-stop solution for those who love noting down daily summaries!
Key Outcomes
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

