What is Data Augmentation?
Data augmentation improves AI model performance by expanding training datasets using transformations and variations. Learn how data augmentation works, common techniques, and why it’s essential for building robust machine learning models.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
The process of creating updated copies of a dataset using pre-existing data is known as data augmentation, and it artificially expands the training set. It comprises adding minor changes to the dataset or using deep learning to create new data points.
When talking about data augmentation, it is mandatory that we understand a thing or two about CNNs.
Convolutionary Neural Networks(CNNs) are a type of deep learning architecture used in computer vision. CNNs are an important component in data augmentation. CNNs classify objects accurately in different orientations, and this is the key concept in data augmentation.
Data Augmentation Vs. Synthetic Data
In our last wiki, we talked about synthetic data in diffusion models. There is a difference between synthetic data and data augmentation.
To be fair, both are generative techniques that augment an existing dataset to enhance machine-learning model performance. Automatically generated wholly fabricated data is referred to as synthetic data. One example is training an object identification model with computer-generated photos instead of real-world data.
Data augmentation, on the other hand, creates duplicates of already-existing data and modifies them to provide more variety and volume to a given set. It uses different techniques, such as flipping, scaling, cropping, contrast, adding noise, and others, to augment the existing dataset.
Why Would You Need Augmentation in Your Data?
Sometimes, in the real world, you have data, but it is limited. You have to train the model with different variations of the data; at that time, data augmentation helps create a diverse variety of data. Let us understand it with a simple example -
You are creating an AI model that can identify different animals. You are provided with a dataset of 500 images. A robust model can identify the data in any condition. To train the model, you need a more diverse dataset.
Suppose you have ten images of giraffes. If the Giraffe is looking right in all 10 of them, the model will be trained to believe that the yellow-colored creature looking right is a Giraffe.
When input with a left-looking Giraffe, the model will not identify it, whereas, in reality, it is a Giraffe.
If data augmentation techniques like rotating, flipping, zooming, cropping, or others are implemented on the data set, adding invariance to the Giraffe images. This will create a much more diverse dataset to train the model.
Benefits of Data Augmentation
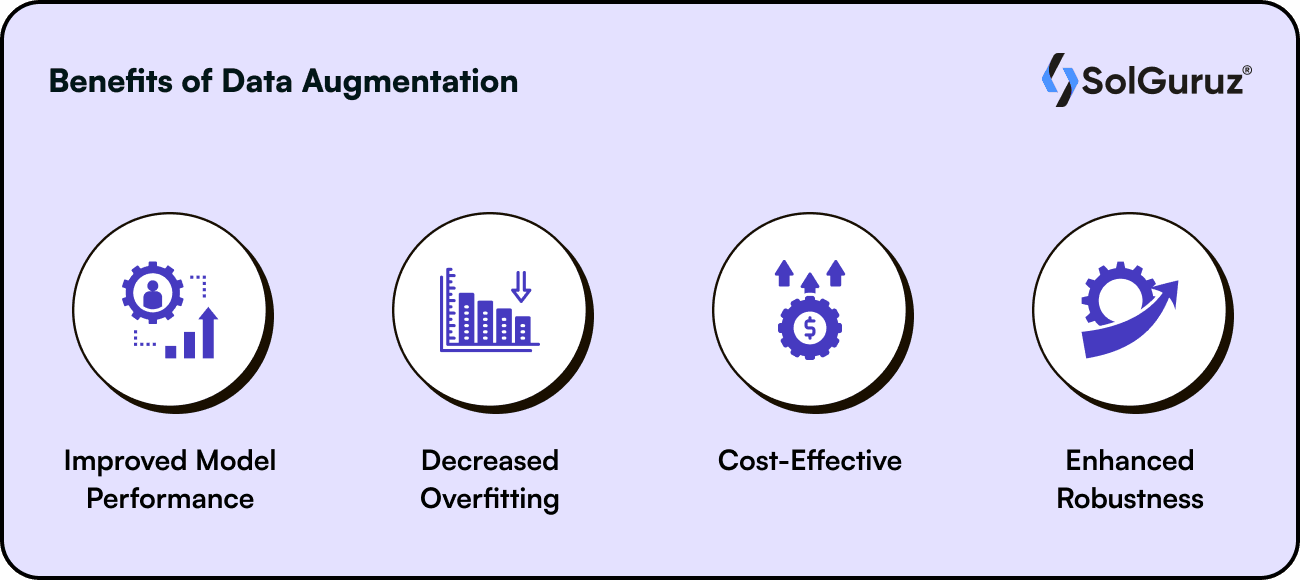
Some benefits of data augmentation are -
1. Improved Model Performance
Augmented data enables the model to learn from a wider range of samples. This makes the model more robust in identifying the samples.
2. Decreased Overfitting
When the training set is more diverse, the model is more likely to generalize to new and unseen data. It prepares the model for unpredictability.
3. Cost-Effective
Gathering new datasets requires more money, hampering the wallet. Creating a more diverse dataset with existing data is a cost-effective and smart use of resources. It drastically reduces the cost of the collection of new data.
4. Enhanced Robustness
The real-world applicability of models trained on augmented data is generally enhanced since they exhibit greater resilience to perturbations in the data.
Data Augmentation in Different Areas
Depending on the type of data and the changes made, data augmentation techniques fall into various categories - a few of the most popular data augmentation areas are -
- Data Augmentation in Images
- Data Augmentation in Video
- Data Augmentation in Audio
- Data Augmentation in Text
What is the Role of Data Augmentation in Generative AI?
Generative AI is crucial to data augmentation because it makes the creation of synthetic data easier. It facilitates the production of realistic data more quickly, protects data privacy, and broadens the diversity of data.
Generative Adversarial Networks (GAN)
Two opposing core neural networks make up the framework of generative adversarial networks or GANs. The discriminator then distinguishes between the real and artificial data samples that the generator produced.
Because GANs concentrate on tricking the discriminator, they gradually increase the generator's output. Data augmentation with extremely dependable samples that closely resemble the original data distribution is possible with data that can mislead the discriminator, which qualifies as high-quality synthetic data.
Variational Autoencoders (VAE)
A variational autoencoder (VAE) is a type of neural network that can help reduce the need for laborious data collection and increase the sample size of core data. A decoder and an encoder are the two networks that are coupled in VAEs. Sample images are fed into the encoder, which converts them into an intermediate form. Using its understanding of the original samples, the decoder takes the representation and uses it to build similar images. Because VAEs can produce data that is very similar to sample data, they can be used to provide diversity while preserving the original distribution of the data.
Data Augmentation Use Cases
We have seen that data augmentation helps in creating diverse datasets. This smart use of data finds its use in many industries. Here are some examples -
Healthcare
Data augmentation is a helpful tool in medical imaging since it enhances diagnostic models that use images to identify, classify, and diagnose diseases. Creating an enhanced image obtains more training data for models, particularly for rare diseases where source data variances are absent. Synthetic patient data is created and used in a way that respects all data privacy concerns and promotes medical research.
Retail
We have seen models used to display products in the retail industry. Here, data augmentation can hugely impact the recognition and classification of products according to visual cues. Through the process of data augmentation, product photos can be artificially varied, resulting in a training set with greater variation in terms of lighting, image backdrops, and product angles.
Finance
Augmentation creates artificial instances of fraud, making it possible for algorithms to be trained to identify fraud more precisely in real-world situations. Larger training data pools that aid in risk assessment scenarios enhance deep learning models' potential to assess risk effectively and forecast future trends.
Natural Language Processing
Text data augmentation is often employed when performance metrics need to be improved, and there is a lack of high-quality data. You can use random insertion and deletion, word embedding, synonym augmentation, and character swapping. Low-resource languages can also benefit from these strategies.
Closing Thoughts
Data Augmentation is proving to be helpful in situations where collecting large datasets is not possible. Healthcare, retail, and many other sectors are seeing the growing use of data augmentation.
Although your data and application must be carefully considered before integrating data augmentation into your process, the advantages greatly exceed the difficulties. Leveraging the full potential of generative AI will require remaining up to date on the newest methods and trends in data augmentation as the field develops.
FAQs
1. What is data augmentation in simple terms?
Data augmentation creates new training data by slightly modifying existing data (e.g., flipping images or rephrasing text) to improve model accuracy.
2. Why is data augmentation used in machine learning?
It helps when data is limited by adding variety, improving accuracy, and reducing overfitting in AI models.
3. How does data augmentation work?
It applies small changes like rotation, noise, or word replacement to existing data while keeping the original meaning intact.
4. What is the difference between data augmentation and synthetic data?
Augmentation modifies existing data. Synthetic data is entirely new data generated using AI models or simulations.
5. What are the most common data augmentation techniques?
- For images: flipping, cropping, and brightness changes.
- For text: synonym replacement, rephrasing.
- For audio: pitch shift, noise addition.
6. What are the different types of data augmentation?
Image, text, audio, and video augmentation are used across computer vision, NLP, and speech systems.
7. How is data augmentation used in Generative AI?
It improves training data quality and helps models like GANs and VAEs generate better outputs.
8. What are the benefits of data augmentation?
Better accuracy, reduced overfitting, improved reliability, and lower data collection costs.
9. What are the limitations of data augmentation?
Incorrect transformations can harm data quality, and they cannot fully replace real-world data.
10. Which industries use data augmentation the most?
Healthcare, finance, retail, automotive, agriculture, and NLP are any fields with limited or sensitive data.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
From Our Portfolio
AI Projects We Have Shipped to Production
SolGuruz has shipped 102+ products across 14 industries. See how SolGuruz built production AI applications - LLM-powered clinical documentation, AI travel planning, healthcare staffing intelligence, and AI journaling - using GPT-4, Claude, and custom ML models at real-world scale.

AI Clinical Notes Platform That Turns 2-Hour Documentation Into One Click
NoteCliniq transforms clinical conversations into HIPAA-compliant SOAP notes in seconds, eliminating 2+ hours of manual documentation daily for busy clinicians.
Key Outcomes
AI-Powered Trip Planner App Solution
Explore how SolGuruz created an AI-powered trip planner app. It is an exclusive AI vacation planner that helps with finding hotels, cabs, places, and complete itineraries.
Key Outcomes
AI-Powered Healthcare Staffing App Solution
Explore our AI-powered healthcare staffing app case study. See how SolGuruz’s expertise transforms nurse staffing challenges into seamless solutions.
Key Outcomes

AI Journaling App Development Solution
Discover with us how we built Dream Story, an AI-powered journaling application that helps manage daily notes by capturing your thoughts and emotions. A one-stop solution for those who love noting down daily summaries!
Key Outcomes
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

