What Is RAG (Retrieval Augmented Generation)? A 2026 Guide
RAG (retrieval-augmented generation) connects language models to external data so they answer from real, current sources instead of memory. This guide explains how RAG works, its types, benefits, challenges, and common RAG use cases across customer support, enterprise search, healthcare, legal, and other industries. It also explores why enterprises adopt RAG to reduce hallucinations and build more trustworthy AI systems.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
Ask a standard AI model about your company's refund policy, and it will guess or admit it doesn't know. It was never trained on your internal documents, and its knowledge stops at a fixed cutoff. That gap is why early enterprise AI projects stalled: the answers sounded confident but couldn't be trusted.
RAG closes that gap. It retrieves the right documents the moment a question is asked, then uses them to write a grounded, source-cited answer, even if the policy changed yesterday.
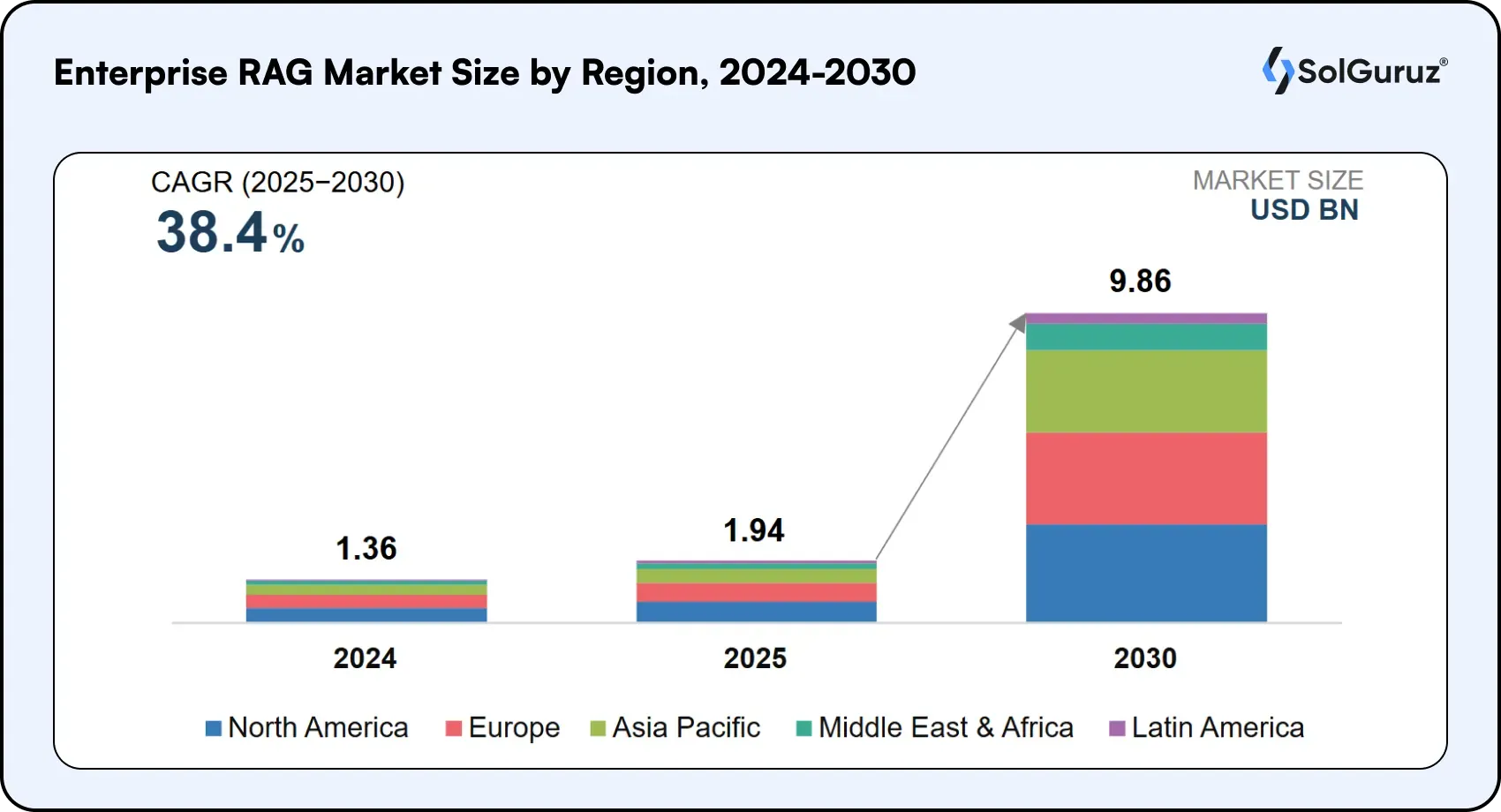
The shift is real: The enterprise RAG market reached USD 1.94 billion in 2025 and is projected to hit USD 9.86 billion by 2030, a 38.4% annual growth rate, with North America leading adoption ahead of Europe and a fast-growing Asia Pacific.
This guide from SolGuruz covers what RAG is, how it works, its types, how it compares to fine-tuning, and where it delivers value. RAG sits at the center of modern generative AI development.
What Is Retrieval-Augmented Generation (RAG)?
Definition: Retrieval-Augmented Generation (RAG) is an AI framework that combines an information retrieval system with a generative large language model. The retrieval part finds relevant facts from an external knowledge source. The generation part uses those facts to write an accurate, context-aware answer.
A plain language model answers only from what it learned during training. That training data is frozen at a point in time, so the model cannot see your internal documents, last week's policy update, or today's pricing. RAG fixes this by giving the model a way to look things up before it answers.
The term was introduced in a 2020 paper led by Patrick Lewis at Facebook AI Research, with coauthors from University College London and New York University. They described RAG as a general-purpose recipe because nearly any LLM can be connected to nearly any external data source using it.
Why RAG Matters: Solving the Hallucination Problem
LLMs are powerful at generating text, but they have three well-known weaknesses that block real-world use:
- Outdated knowledge. Training data is fixed, so the model misses anything newer than its cutoff.
- Hallucination. When the model lacks the right information, it can produce confident answers that are wrong.
- No sources. A plain model rarely shows where an answer came from, which makes it hard to trust in regulated work.
RAG addresses all 3. Because the model answers from retrieved documents, responses stay current, stay grounded in fact, and can include citations that users can verify. One widely cited example of hallucination risk: Google's early Bard demo gave incorrect information about the James Webb Space Telescope. Source grounding through RAG is how teams reduce exactly this kind of error.
RAG does not remove hallucination completely. Retrieval quality, document relevance, and how the prompt is built all affect the outcome. But it reduces errors significantly compared with an ungrounded model.
How Does RAG Work? A Step-by-Step Breakdown
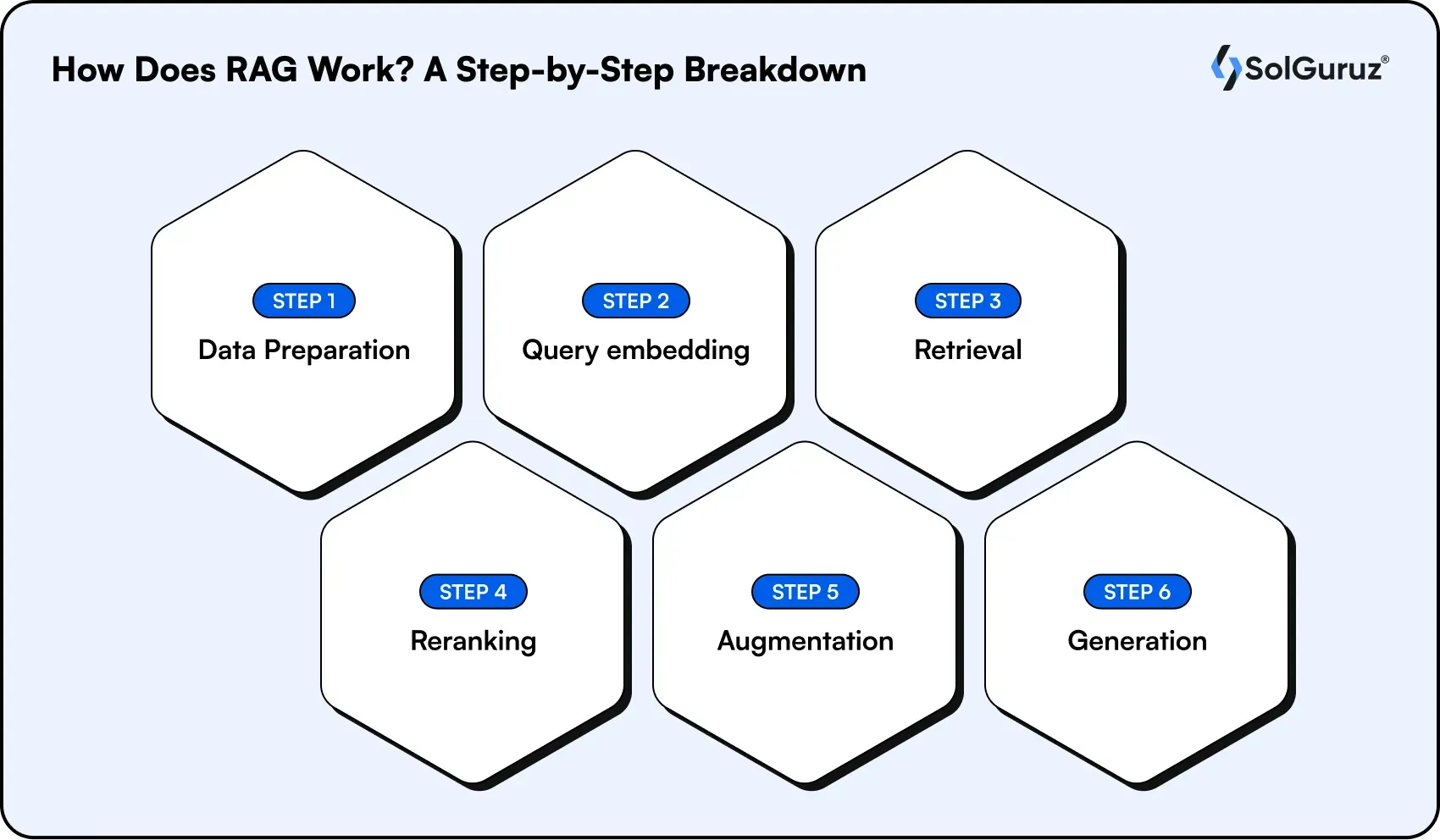
A RAG system runs in two phases. First, an offline indexing phase prepares the knowledge base. Then, an online phase answers questions in real time. Here is the full flow.
1. Data preparation
Source documents (policies, manuals, support tickets, product data) are cleaned and split into smaller chunks. Each chunk is converted into a numeric representation called an embedding and stored in a vector database, along with metadata like title, date, and access level.
2. Query embedding
When a user asks a question, the question is converted into the same kind of embedding so it can be compared against the stored data.
3. Retrieval
The system searches the vector database and pulls the most relevant chunks, usually measured by similarity. Semantic search of this kind is far more accurate than keyword-only search for long, natural questions.
4. Reranking
A second scoring step reorders the retrieved chunks so the most relevant evidence rises to the top and noisy results are dropped. This step is what separates a basic system from a production one.
5. Augmentation
The best chunks are added to the prompt as context, alongside the user's original question.
6. Generation
The LLM reads the question plus the retrieved context and writes a grounded answer, often with citations pointing back to the sources.
A practical detail that matters now: latency used to be RAG's biggest weakness, because retrieval added a step to every query. Faster vector databases, smarter caching, and more efficient embedding models have brought response times down to roughly the level of a standard API call for most use cases.
Types of RAG: From Basic to Agentic
RAG is not one fixed design. As it matured, several patterns emerged, each suited to a different level of complexity. These are the ones worth knowing.
Type | What It Does | Best For |
| Naive RAG | Single retrieval step, no reranking or filtering. The model answers from whatever is retrieved. | Simple prototypes and small, clean knowledge bases |
| Advanced RAG | Adds reranking, filtering, and query rewriting to improve relevance. Most production systems today. | Customer support, internal Q&A at scale |
| Multi-Step RAG | Retrieves and reasons in several passes for complex or multi-hop questions. | Research, troubleshooting, layered questions |
| GraphRAG | Uses a knowledge graph as the retrieval layer, so the system reasons over entities and relationships. | Multi-hop reasoning, regulated domains needing traceability |
| Agentic RAG | RAG is embedded in a multi-agent system, where agents handle retrieval, validation, and synthesis. | Enterprise AI agents, the dominant 2026 direction |
The clear shift in 2026 is toward Agentic RAG. Instead of one rigid retrieve-and-answer pipeline, specialized agents decide what to retrieve, check the evidence, and re-query when confidence is low. This is the same architecture pattern behind modern AI agent development, where agents need an accurate, current context to reason over.
RAG vs Fine-Tuning vs Semantic Search
These 3 terms get mixed up often. They are related but solve different problems.
Approach | What It Is | When to Use |
| RAG | Retrieves external data at query time and feeds it to the LLM | Knowledge that changes often needs citations |
| Fine-tuning | Retrains the model's weights on a specialized dataset | Fixed tasks, changing tone or behavior |
| Semantic search | Finds and returns relevant content by meaning, no answer written | When you only need the documents, not a synthesized answer |
The simplest way to hold the distinction: Semantic search finds the right content. RAG uses that content to write an answer. Fine-tuning changes how the model thinks. Semantic search is actually one component inside a RAG pipeline, the retrieval step.
Fine-tuning works best when the goal is a specific task, such as classifying customer sentiment, and little outside knowledge is needed. RAG is the better choice for knowledge-heavy work that depends on current or proprietary information. Many production systems combine both. If you are unsure which path fits your product, an AI consulting engagement can map your use case to the right approach before you commit to a budget.
Key Benefits of Implementing RAG
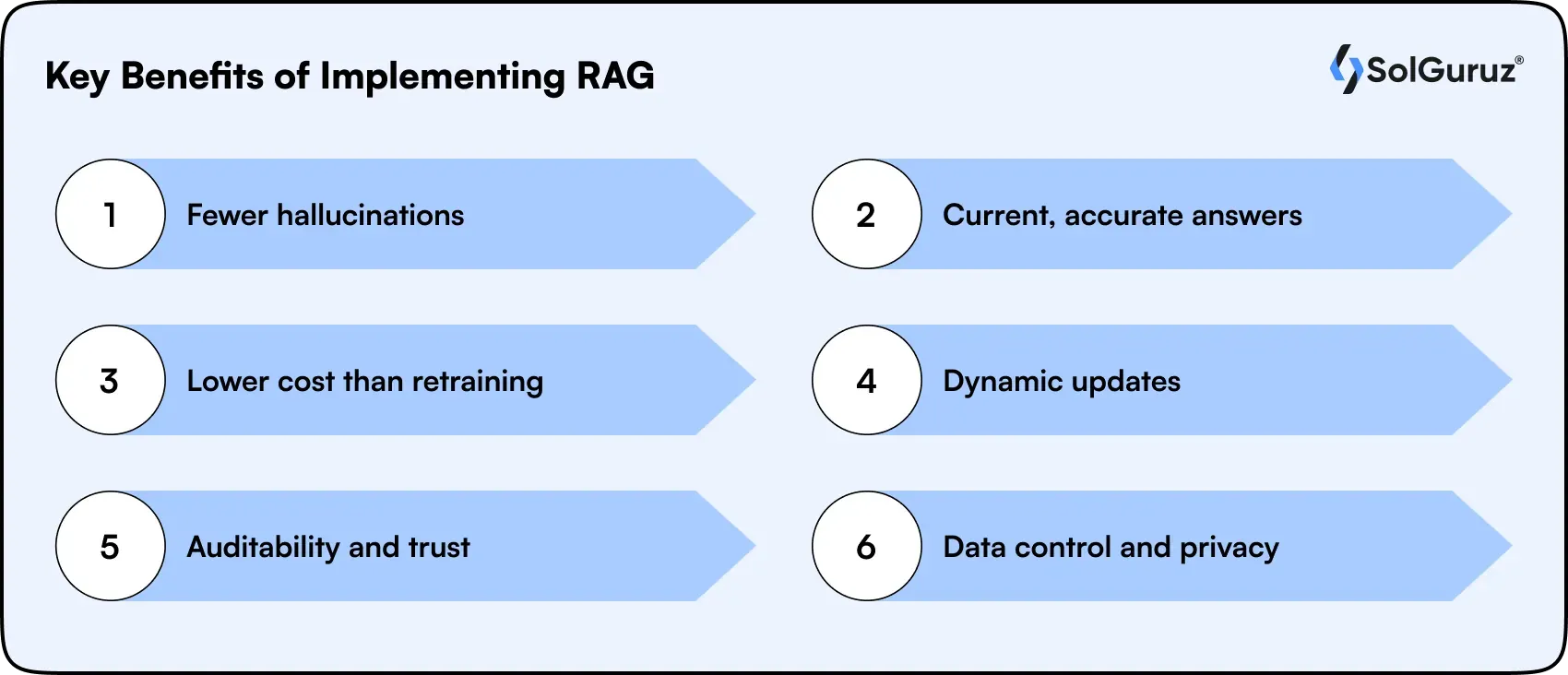
For businesses adopting generative AI, RAG offers advantages that a standalone LLM cannot match.
Fewer hallucinations
A dedicated knowledge base grounds answers in fact and cuts down on confident but wrong outputs.
Current, accurate answers
Responses reflect updated data, not just old training data, and citations make them verifiable.
Lower cost than retraining
Updating a knowledge base is far cheaper than retraining a neural network on fresh data.
Dive in and explore: How To Run LLM locally
Dynamic updates
Change the source, and the next answer reflects it. No retraining cycle required.
Auditability and trust
Every answer can be traced back to specific source documents, which compliance and legal teams require.
Data control and privacy
Sensitive data stays in your controlled knowledge base rather than being baked into model weights.
Together, these advantages make RAG the preferred approach for building reliable enterprise AI.
Common Challenges With RAG (And Why It Sometimes Fails)
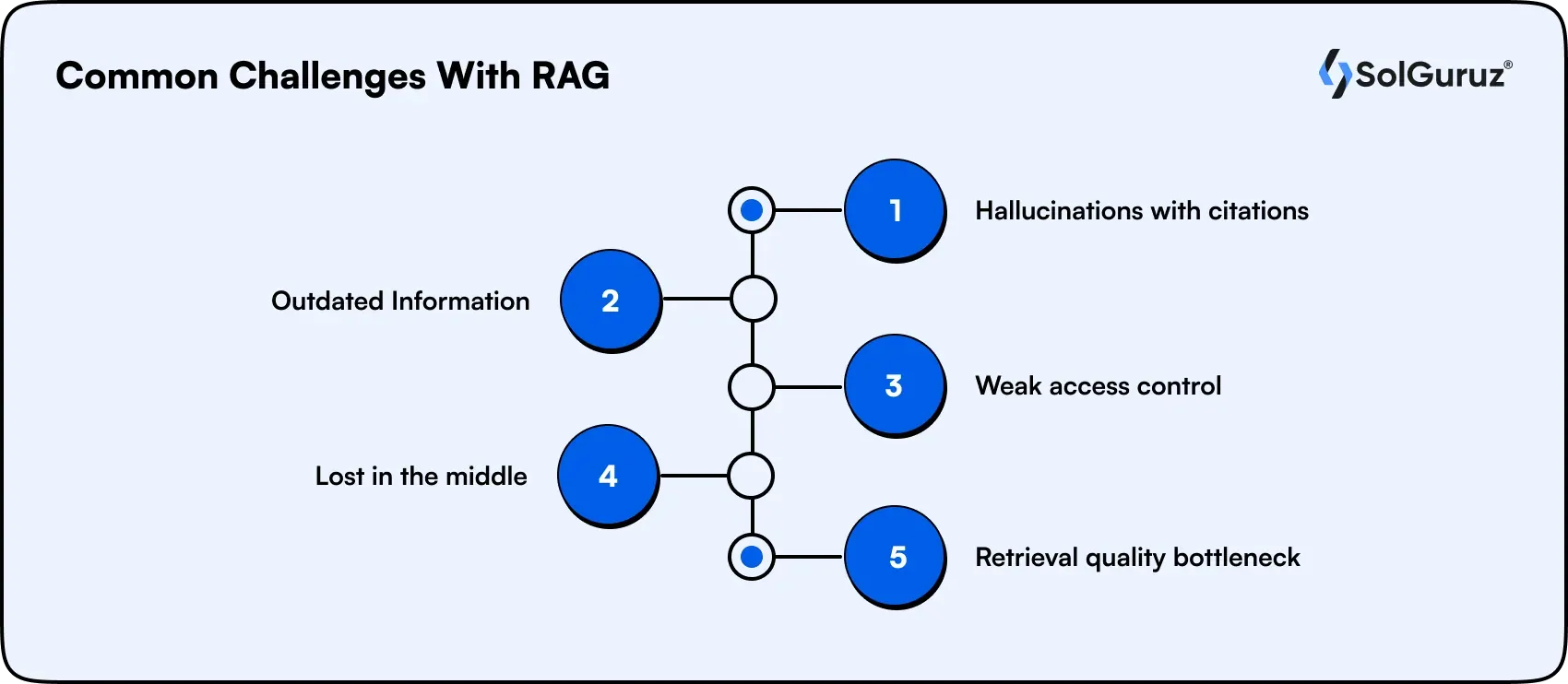
RAG is powerful, but naive implementations break at scale. Knowing the failure modes upfront is what separates a working system from a frustrating one.
1. Hallucinations with citations
The model can still fabricate a conclusion even when it retrieved documents, usually because the retrieved chunks were incomplete or off-target. The citation creates false confidence, which makes this failure especially risky.
2. Outdated Information
If the index is not kept in sync with source systems, RAG confidently serves outdated information. Policies and numbers change; the index has to keep up.
3. Weak access control
Flat document stores without proper permissions can surface content to users who should not see it, which becomes a compliance problem.
4. Lost in the middle
Stuffing too many chunks into the prompt buries the right answer under noise. More context is not always better.
5. Retrieval quality bottleneck
The system is only as good as what it retrieves. Poor chunking or a weak embedding model produces weak answers, no matter how strong the LLM is.
The lesson behind all of these: the knowledge source, not the model, is where most RAG success or failure is decided.
Real-World RAG Applications Across Industries
RAG shows up across industries wherever accuracy and current information matter. The most common practical applications:
1. Customer support chatbot
Assistants answer from a company's real knowledge base, product docs, and past tickets, so replies are accurate instead of generic. This is the most widespread use in enterprise today.
2. Enterprise knowledge search
Employees ask questions about HR policies, runbooks, compliance guidelines, and internal wikis, and get a direct answer instead of digging through documents.
3. Healthcare
Clinical teams surface guidelines, research, and patient documentation with source citations. Studies report measurable gains in accuracy for medical question answering when retrieval is added.
4. Legal and compliance
Teams summarize case law and review contracts faster, with answers tied back to the original text, which preserves traceability.
5. Financial research
Analysts pull insights from earnings calls, reports, and market data with traceable sourcing.
6. Developer and technical support
RAG systems ingest documentation, release notes, and past issues to give engineers precise, version-aware answers. This pairs naturally with AI-assisted software development, where teams use grounded AI to move faster without losing accuracy.
Why Enterprises Need RAG in 2026
Enterprises adopt RAG to push past the limits of plain LLMs in settings where accuracy and timeliness are non-negotiable. Pre-trained models alone bring real problems: hard-to-expand knowledge, outdated data, missing references, hallucination, and the risk of leaking sensitive information.
RAG addresses each of these while keeping the language model's strengths. The adoption data reflects how seriously enterprises now take it: highly regulated sectors such as healthcare, finance, legal, and government lead the way because they require fact-checked, explainable outputs.
Companies that deployed RAG report meaningful efficiency gains in knowledge-heavy workflows, which is why the technology has moved from experiment to production-critical architecture this year.
How SolGuruz Approaches RAG Development
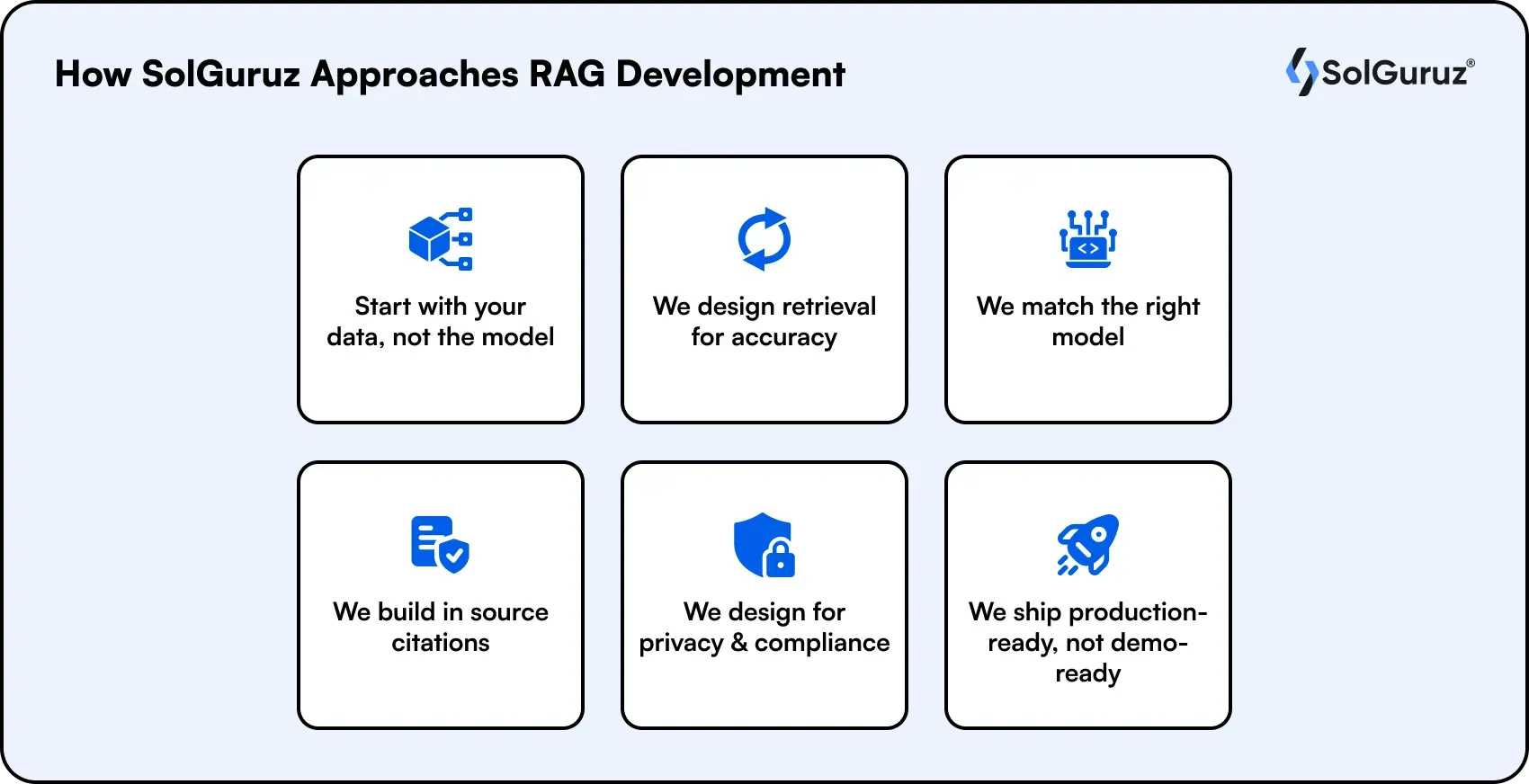
At SolGuruz, we build RAG systems that hold up in production, not just in a demo. Drawing on the expertise (shared through our Generative AI Hub), our approach focuses on building retrieval pipelines that deliver accurate, traceable, and context-aware responses from your business data. Here's how we work.
1. Start with your data, not the model.
Every engagement begins with a discovery phase that maps your knowledge sources, data quality, and access rules before any architecture is chosen.
2. We design retrieval for accuracy.
We tune chunking, embeddings, and reranking so the system retrieves the right context, since retrieval quality is what makes or breaks a RAG system.
3. We match the right model.
We are model-agnostic, working across OpenAI, Anthropic Claude, and open-source models, and we test embedding and reranking choices against your real data rather than defaulting to one tool.
4. We build in source citations.
Our RAG systems return answers users can trace back to the source, which is essential for regulated work in healthcare, finance, and legal.
5. We design for privacy and compliance.
Sensitive data stays in your controlled knowledge base with proper access controls, never baked into model weights.
6. We ship production-ready, not demo-ready
Using our AI-assisted software development workflow, we handle latency, monitoring, and accuracy testing so the system performs under real user load, with a fully scoped estimate produced before development begins.
Final Thoughts
RAG has become the practical foundation for reliable enterprise AI. Grounding language models in real, current, source-backed data, it solves the accuracy and trust problems that kept LLMs out of serious production work.
With adoption now reaching mainstream levels and the technology being faster and cheaper than ever, RAG is no longer a niche technique. It is how trustworthy AI gets built, and the next wave, Agentic RAG, is already extending it into autonomous systems.
If you are planning an AI product that needs accurate, explainable answers from your own data, the right architecture matters. SolGuruz provides AI consulting services, custom RAG development, and options to hire generative AI engineers who can design, build, and deploy reliable, production-ready AI solutions tailored to your business requirements.
FAQs
1. What is Retrieval-Augmented Generation (RAG) in simple terms?
RAG is an AI technique that lets a language model look up relevant information from an external source before answering. It combines retrieval (finding the right documents) with generation (writing the answer), so responses are accurate and grounded in real data instead of being guessed from memory.
2. What is RAG in generative AI?
In generative AI, RAG connects a generative LLM to a knowledge base. The model retrieves relevant facts at query time and uses them as context to generate a grounded response. This makes generative AI usable for enterprise work where accuracy and current information matter.
3. How does RAG work?
RAG prepares documents into embeddings stored in a vector database, embeds the user's question, retrieves the most relevant chunks, reranks them, adds them to the prompt, and the LLM generates an answer from that context, often with citations.
4. What are the key components of RAG?
A RAG system has three core parts: a knowledge index that stores the chunked documents, a retriever that finds relevant content, and a generator (the LLM) that turns retrieved context into a readable answer.
5. What are common RAG use cases?
Common RAG use cases include customer support chatbots, enterprise knowledge search, healthcare information retrieval, legal research, compliance workflows, financial analysis, and developer support systems.
6. How does RAG reduce hallucinations?
RAG gives the model real, retrieved context to answer from, so it relies less on assumptions from training data. It reduces hallucinations significantly, though retrieval quality still matters, and it cannot remove them completely.
7. What is the difference between RAG and fine-tuning?
RAG adds knowledge at query time by retrieving external data, so you update the source instead of the model. Fine-tuning retrains the model's weights for a specific task. RAG fits changing knowledge; fine-tuning fits fixed, task-specific behavior.
8. What is the difference between RAG and semantic search?
Semantic search finds and returns the most relevant content by meaning. RAG goes a step further: it takes that retrieved content and uses an LLM to write a synthesized answer. Semantic search is actually the retrieval step inside a RAG pipeline.
9. What data sources can RAG use?
RAG can use documents, databases, APIs, and web content. It commonly relies on a vector database for fast semantic search, which finds information by meaning rather than exact keyword matches.
10. What are the limitations of RAG?
RAG performance depends on data quality and retrieval accuracy. Poorly chunked or outdated sources lead to weak answers. It also needs proper infrastructure, a vector database, embeddings, reranking, and ongoing data management to work well.
11. Is RAG still relevant in 2026?
Yes. Adoption reached a tipping point this year, with a majority of large enterprises running RAG in production. As AI agents grow, RAG becomes more important as the layer that feeds them accurate, current data.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
From Our Portfolio
AI Projects We Have Shipped to Production
SolGuruz has shipped 102+ products across 14 industries. See how SolGuruz built production AI applications - LLM-powered clinical documentation, AI travel planning, healthcare staffing intelligence, and AI journaling - using GPT-4, Claude, and custom ML models at real-world scale.

AI Clinical Notes Platform That Turns 2-Hour Documentation Into One Click
NoteCliniq transforms clinical conversations into HIPAA-compliant SOAP notes in seconds, eliminating 2+ hours of manual documentation daily for busy clinicians.
Key Outcomes
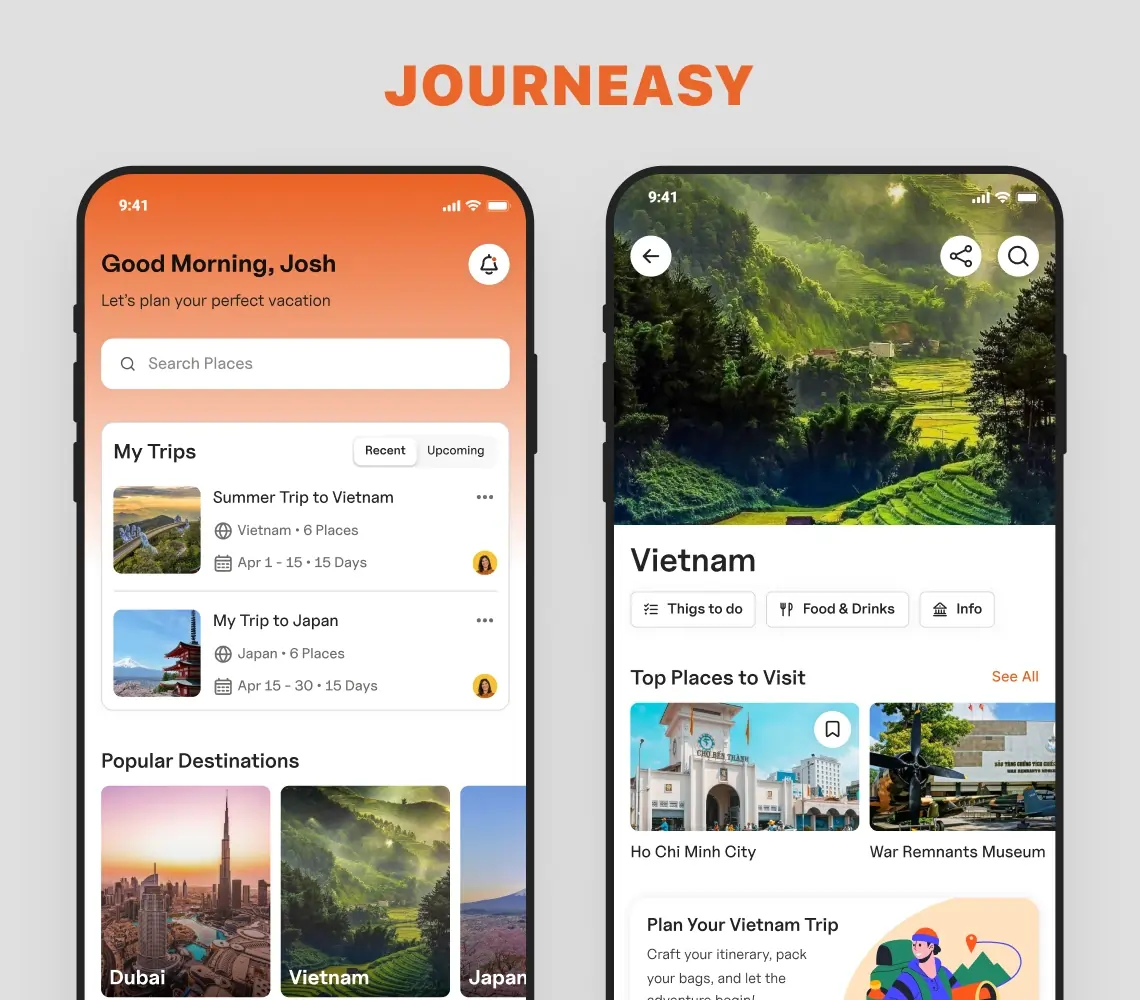
AI-Powered Trip Planner App Solution
Explore how SolGuruz created an AI-powered trip planner app. It is an exclusive AI vacation planner that helps with finding hotels, cabs, places, and complete itineraries.
Key Outcomes
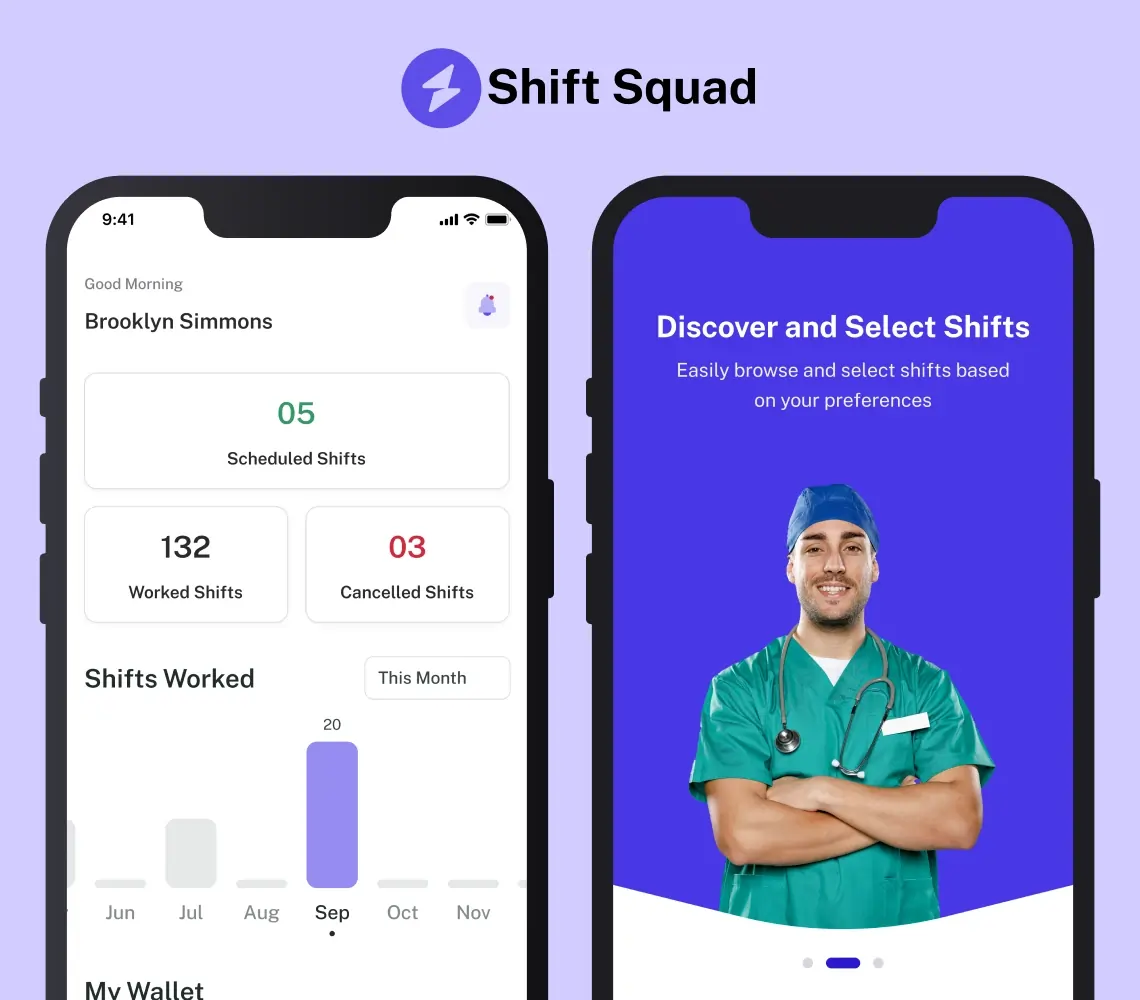
AI-Powered Healthcare Staffing App Solution
Explore our AI-powered healthcare staffing app case study. See how SolGuruz’s expertise transforms nurse staffing challenges into seamless solutions.
Key Outcomes

AI Journaling App Development Solution
Discover with us how we built Dream Story, an AI-powered journaling application that helps manage daily notes by capturing your thoughts and emotions. A one-stop solution for those who love noting down daily summaries!
Key Outcomes
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

