The Potential of Multimodal AI
Multimodal AI processes and understands multiple data types like text, images, audio, and video together. Learn how multimodal systems work, real-world examples, and why they enable more human-like and context-aware AI experiences.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
Experts defined “Modals” as the different human sensory techniques like language, text, touch, seeing, and listening. When considering AI, modality means different data types. Data types like text, image, audio, video, and others can be used as input.
So, unimodal will simply mean one data type as an input and output. Similarly, multimodal means multiple data types as input to the generative AI model. The model then produces results in different modalities corresponding to the input.
What is Multimodal AI?
Within artificial intelligence, multimodal learning aims to enhance robots' ability to learn by using copious amounts of textual data along with other forms of information, sometimes referred to as sensory data, such as photos, videos, or audio recordings. This enables models to discover new associations and patterns between text descriptions and the corresponding pictures, videos, or audio.
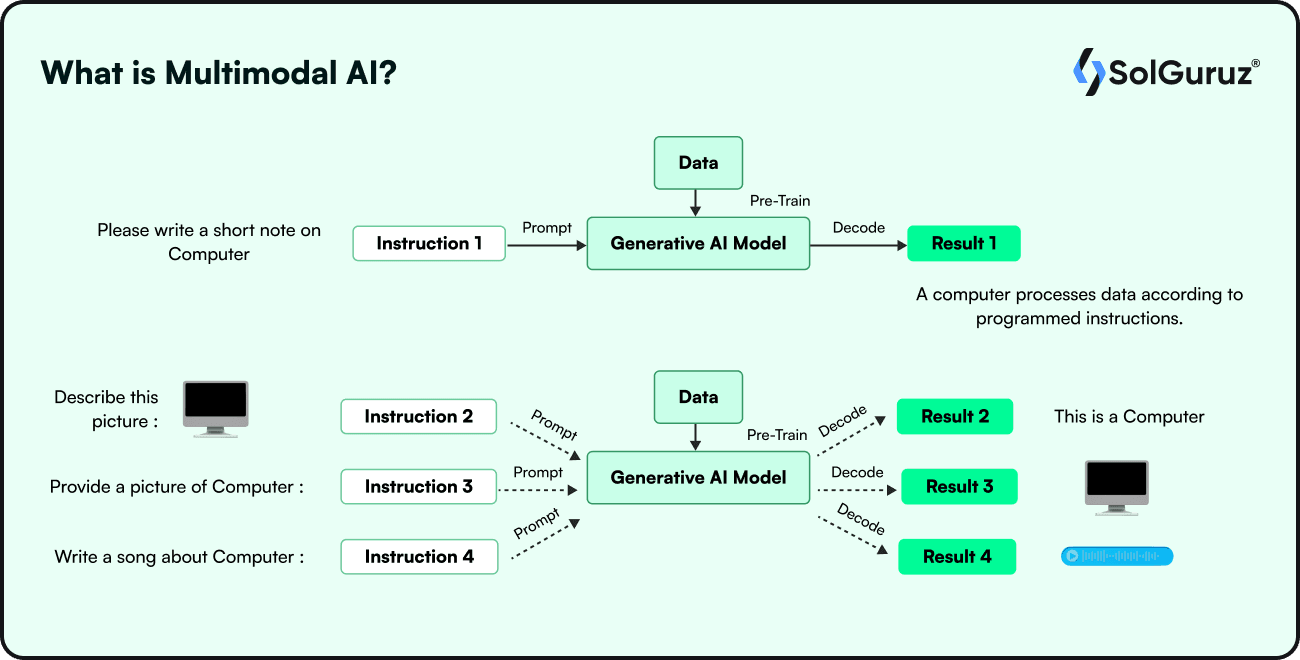
The difference between multimodal and unimodal
The picture here clearly illustrates the difference between multimodal and unimodal.
How Does it Work?
We have established in our series now that gen AI models are great learners. They are trained on data, and they learn and produce results from the training. Multimodal AI models are no different. They are also fed data; they learn and then produce results.
Technical explanation
The basic concept of multimodal learning is cross-modal learning. In this concept, the models are trained to learn the relationships between various modalities.
Multimodal AI systems are trained to recognize patterns in several data input formats. There are three main components to these systems:
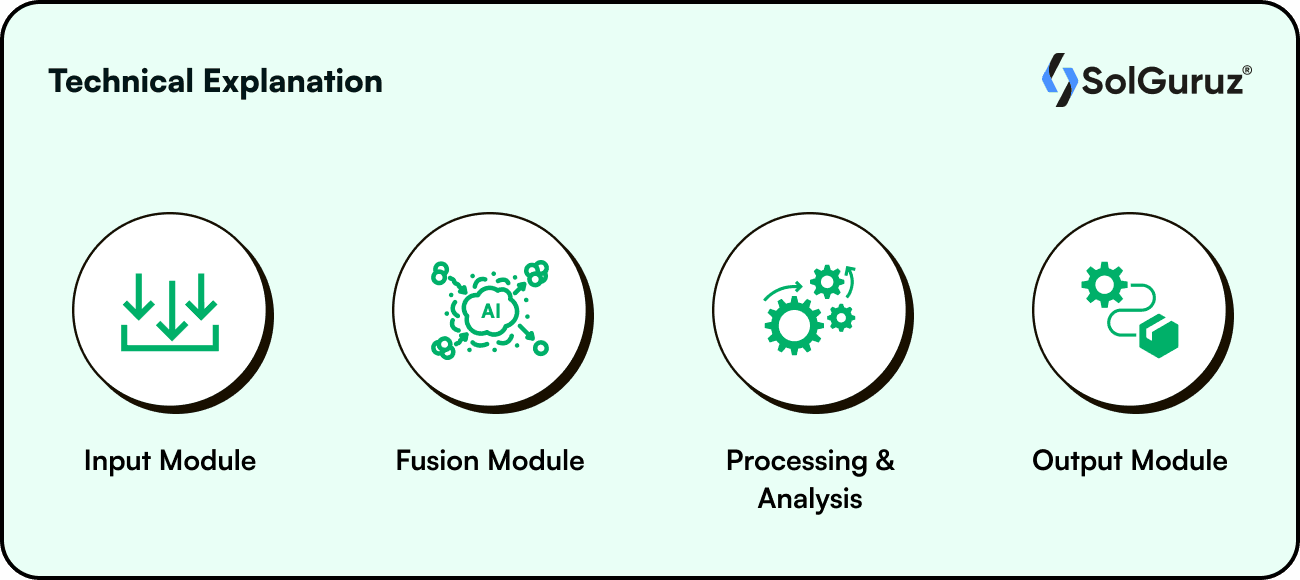
In reality, a multimodal AI system is made up of numerous unimodal neural networks. The input module, which receives various kinds of data, is composed of these.
Fusion combines data from multiple encoders to ensure the multimodal model maximizes each modality's advantages. Various methods are used in fusion, including early fusion, hybrid fusion, late fusion, and cross-modal fusion. The output module is in charge of producing the ultimate result or forecast using the data combined and processed by the architecture's earlier phases. These differ substantially based on the first input.
Challenges to Implement Multimodal
The tech is in its nascent stage. Many challenges were faced during its implementation. Some of the disadvantages of multimodal AI are-
Data Integration
Since data from diverse sources will not always have the same formats, combining and syncing various types of data can be difficult. It might also be challenging and time-consuming to guarantee the smooth integration of several modalities while upholding constant data quality and temporal alignment throughout the processing pipeline.
Features Representation
Every modality has distinct features and ways of representing them. For instance, text may require word embeddings or large language models (LLMs). Images may require feature extraction techniques such as convolutional neural networks (CNNs). Sometimes multimodal AI makes the results a bit complex that are difficult to understand.
Scalability and Dimensionality
Since each modality adds a unique set of information, multimodal data is usually high-dimensional and lacks dimensionality reduction techniques. The dimensionality of the data increases substantially with the number of modalities. This poses problems for the scalability, memory needs, and computational complexity of the AI models and the algorithms they employ to handle data.
Model Building and Fusion Methods
Research is still being done on creating efficient structures and fusion methods to integrate data from various modalities. Achieving the ideal balance between cross-modal interactions and modality-specific processing is a challenging endeavor that calls for thorough planning and extensive testing.
Availability of Labeled Data
Labeled data covering several senses is frequently needed for multimodal AI data sets. Large-scale multimodal training dataset maintenance can be costly, and gathering and annotating data sets with a variety of modalities presents unique obstacles.
Benefits of Multimodal AI
Multimodal AI has been more popular than unimodal AI. Here are a few advantages of multimodal AI-
1) Enhanced Accuracy
Multimodal AI can improve understanding of any topic. It can achieve resilience by utilizing input from many senses. For instance, by combining text, image, and audio modalities, you can get a more thorough understanding of user sentiment when evaluating customer feedback on a product.
2) Increased Interaction & Improved UX
Multimodal AI can improve user experience (UX) by giving users more options for interacting with the system. Virtual assistants are some of the best examples of increased interactions and enhanced user experience. Whether they are voice assistants, gestures, or text, they are designed to increase accessibility and convenience.
3) Robustness Against Noise
Multimodal AI can withstand noise and variability in the input data better by combining information from several modalities. For instance, even in the event of a deteriorating audio signal or a speaker's mouth being partially concealed, a speech recognition system that integrates visual and auditory data can still identify speech.
4) Effective Use of Resources
By allowing the system to concentrate on the most pertinent facts from each modality, multimodal AI can assist in the more effective use of computing and data resources. For instance, integrating text, photos, and metadata can assist minimize the quantity of unnecessary data that needs to be processed in a system that evaluates social media posts for sentiment analysis.
Use cases of Multimodal AI
Multimodal AI has different applications in many industries. Here are a few industries that are successfully implementing the multimodal AI -
Healthcare
Multimodal AI promotes improved patient results through tailored treatment plans, and quicker and more accurate diagnoses. Multimodal AI evaluates several data modalities, such as pictures, data, symptoms, background, and patient histories. This allows healthcare practitioners to make well-informed judgments more rapidly and effectively.
Agriculture
Multimodal AI can be used to forecast yields, monitor crop health, and improve agricultural techniques. Farmers may optimize irrigation and fertilizer application. This leads to increased crop yields and lower costs. Combining satellite imaging, weather data, and soil sensor data gives an estimation of soil health and farm health. In turn, providing a deeper understanding of crop health.
Retail
The retail sector targets the supply chain management, product recommendations, and customer experience personalization, through multimodal AI. The analysis of many data modalities, such as consumer behavior, preferences, and purchase history helps the retail sector in improving efficiency. Multimodal AI offers retailers significant insights that are leveraged to enhance operational efficiency and revenue growth.
Manufacturing
Manufacturing companies can use multimodal AI to optimize their production processes. They are also helpful in providing better products to customers. By integrating different input and output modes, such as speech, vision, and movement, the manufacturing sector reaps the maximum benefit of multimodal AI. This is why multimodal AI is becoming increasingly popular in the industry.
The use of multimodal AI is not limited to these industries. Industries like entertainment, automotive, learning, education, and many more are the successful use cases of multimodal AI. Many other industries are working on multimodal AI.
Conclusion
It won’t be an overstatement that Multimodal AI systems are the future of AI. Its ability to optimize operations and streamline procedures will enable businesses to operate more successfully and productively. It will result in increased profitability and process growth. We must seize this technology's great potential and apply it to the good of society.
Multimodal systems help us understand the world more closely in a way closer to what humans do.
FAQs
1. What does multimodal mean in AI?
In AI, multimodal means the system can process and understand multiple types of data at the same time, such as text, images, audio, video, and sensor inputs. This helps AI generate more accurate and context-aware results compared to single-input models.
2. When is an AI model considered multimodal?
An AI model is considered multimodal when it can accept, interpret, and generate outputs using more than one type of data input. For example, an AI system that understands both text and images is a multimodal model.
3. What is an example of a multimodal AI system?
Examples of multimodal AI systems include voice assistants, autonomous vehicles, medical diagnosis platforms, image captioning tools, and AI models like GPT-4 Vision that can process both text and images together.
4. What is multimodal generative AI?
Multimodal generative AI refers to AI systems that can create outputs using multiple input formats. For example, it can generate text from images, create images from text prompts, or analyse voice and video together to produce useful responses.
5. How does multimodal AI process text, images, and audio together?
Multimodal AI uses separate input modules to process each data type individually. A fusion layer then combines the information, helping the model understand relationships between modalities before generating the final output.
6. How is multimodal AI different from other AI models?
Traditional AI models often work with one type of data only, such as text or images. Multimodal AI combines multiple data sources, allowing deeper understanding, better decision-making, and stronger real-world performance.
7. What advantage does multimodal AI offer over single-modality tools?
Multimodal AI improves accuracy, reduces dependency on one data source, handles noisy inputs better, and creates more natural human-like interactions. This makes it more effective than single-modality AI systems.
8. What are the main challenges in implementing multimodal AI?
The biggest challenges include data integration, fusion complexity, scalability, high computational cost, feature representation, and collecting high-quality labeled data across different modalities.
9. What industries benefit the most from multimodal AI?
Healthcare, finance, retail, manufacturing, agriculture, automotive, and education benefit greatly from multimodal AI because it improves automation, prediction, decision-making, and customer experience.
10. Is Gemini an example of multimodal AI?
Yes, Gemini is a multimodal AI model because it can process and understand text, images, audio, code, and other data types together, making it more advanced than traditional text-only AI systems.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

