What is Large Language Model (LLM)?
Large language models (LLMs) are AI systems that understand and generate human-like text using deep learning. This blog explains how LLMs work, their key use cases, benefits, and limitations. It also highlights how businesses use them to automate workflows and improve efficiency while managing risks like bias and data privacy.

Summarise with AI
Short on time? Let AI do the work. Get the key points.
Key Takeaway
|
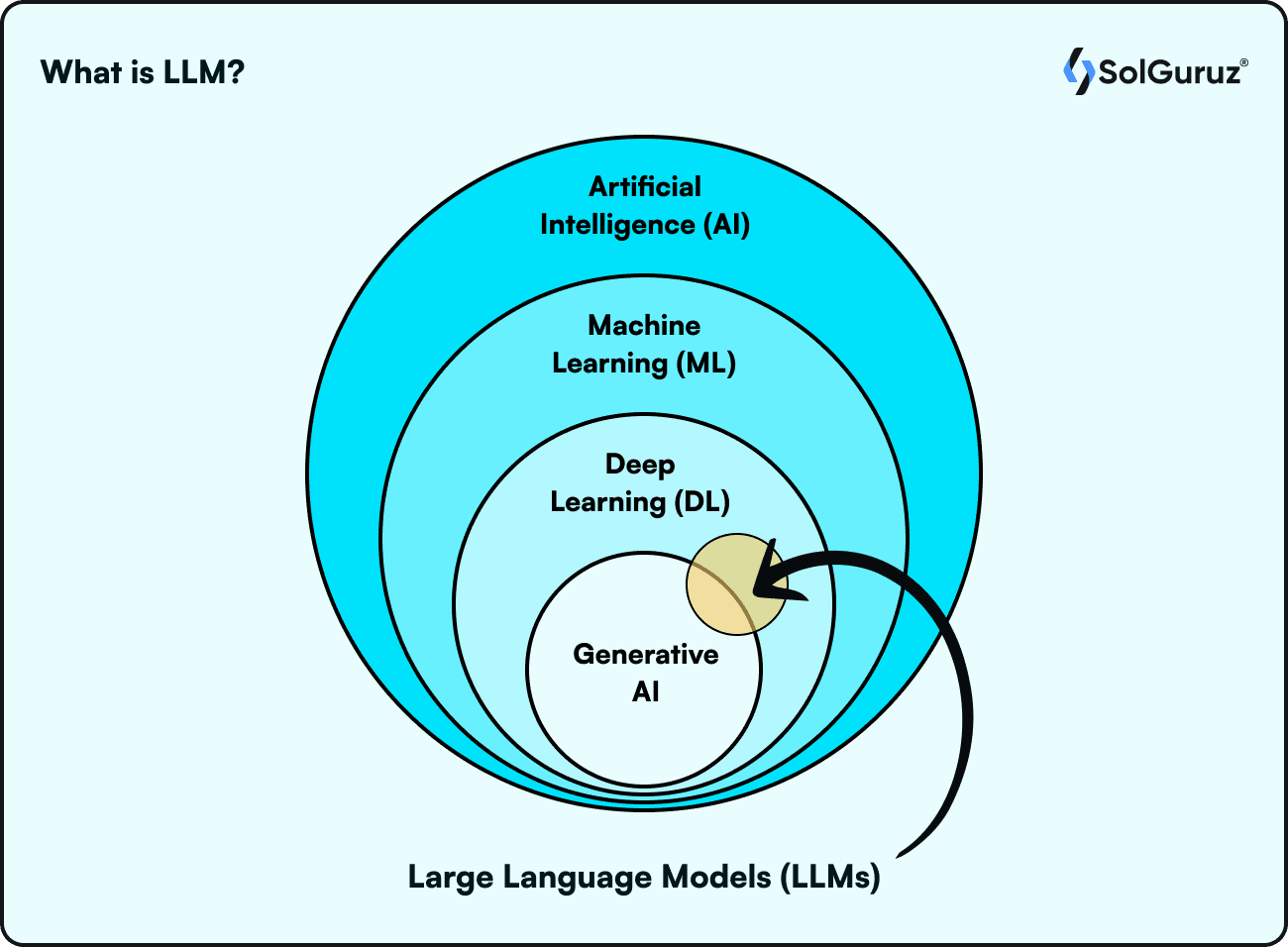 A large language model (LLM) is an artificial intelligence (AI) program that can recognize and produce text. It is at the intersection of Machine Learning and Deep Learning.
A large language model (LLM) is an artificial intelligence (AI) program that can recognize and produce text. It is at the intersection of Machine Learning and Deep Learning.
These are neural networks trained on large datasets and a very large number of parameters. The name breaks into three parts –
Large refers to large datasets to be trained on and a large number of parameters.
Language refers to the natural language used.
Models refer to the foundation models. LLMs are typically transformer models with an encoder and decoder within them. For more details, please refer to our Generative AI section.
Deep learning is a subset of machine learning that LLMs use to learn how words, phrases, and characters work together. Through the probabilistic examination of unstructured data, deep learning eventually allows the model to identify differences between content without the need for human interaction.
After that, LLMs undergo additional training through tuning, which includes prompt-tuning or fine-tuning to the specific activity that the programmer wants them to perform, such as translating text across languages or interpreting questions and producing answers.
Generative AI generates original content like images, audio, video, or text on given proper prompts. However, LLMs are just a small part of Gen AI that corresponds to the text part. LLMs are trained to generate different kinds of text like poems, articles, essays, QnA, video summarization, or translating from one language to another.
How Does it Work?
Essentially, an
LLM is – Data + Architecture + Training
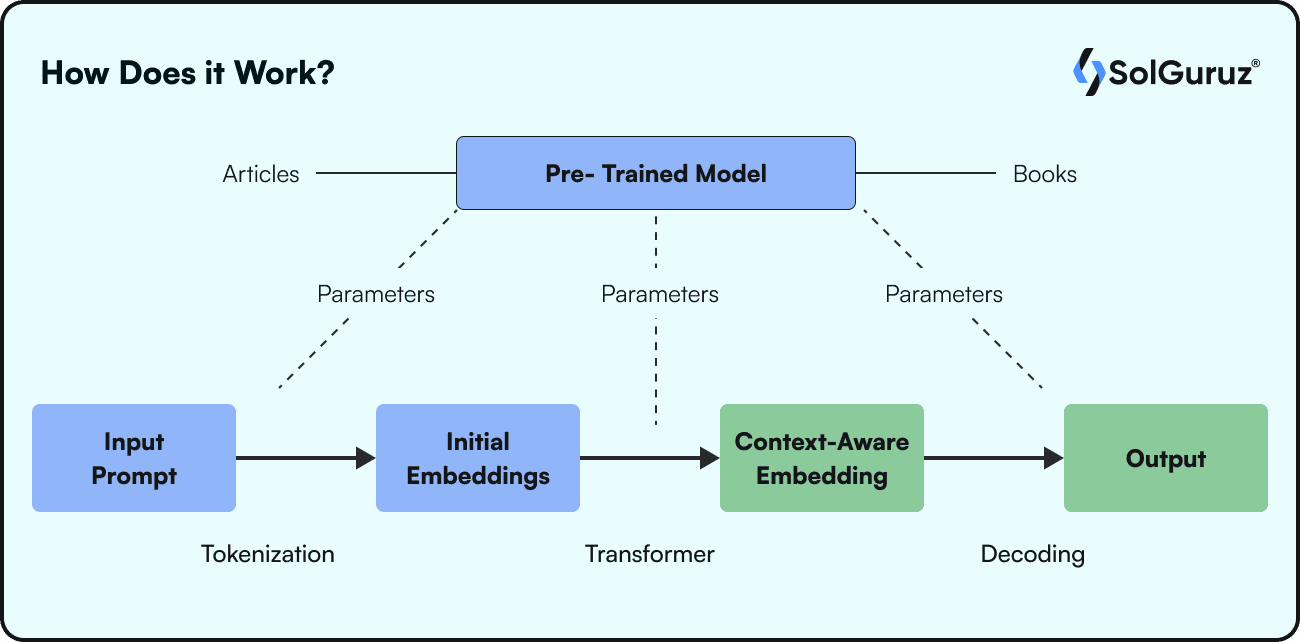
To understand how LLMs work, we need to understand a few basics first.
An LLM's training procedure is significantly responsible for its effectiveness. In this stage:
Pre-training: To enable the model to understand the relationships and patterns among words, it is subjected to massive volumes of text data (from books, papers, and web pages) internet in general. The more data it is trained on, the more refined results it produces. It gets more adept at producing original content with time.
It gains the ability to predict a sentence's following word while doing this. If given a prompt, "The sky is ___,” for example, the model might predict "vast" or “blue.” The more trained it is, the better the output will be according to the context. The machine picks up language, world facts, reasoning skills, and even certain biases from billions of these predictions. The biases in the results come from the data the model is fed.
Fine-tuning: The model can be made to specialize in specific categories or knowledge domains by refining it on a smaller dataset following the first pre-training. This aids in coordinating the model's outputs with the intended results. For instance, if a model is fine-tuned with healthcare data it is more likely to produce relevant results than a non-fine-tuned model.
Once a question or any instruction (Input Prompt) is given to the LLM. The words are broken into tokens. Tokenization is the process of converting words into numerical values, depending on the training. This input prompt after tokenization is fed to the initial embeddings. Depending on the architecture, the output is then fed to the context-aware embeddings. In this case, the architecture is a “Transformer model,” meaning it takes an input, puts it through the encoder, then the decoder, and the result is generated.
The context-aware embeddings are in the form of numerical values. These numbers are again decoded to natural language to give human-understandable output.
All this time, the parameters from the pre-trained model are continuously fed at every stage to refine and process the input.
Why are LLMs Essential?
Large Language Models have great flexibility. One model is capable of carrying out a wide range of functions, including answering inquiries, summarizing papers, translating across languages, and finishing sentences. LLMs have the power to change how consumers use virtual assistants and search engines, as well as how information is created.
Even though they're not flawless, LLMs are showing a remarkable capacity for prediction based on a comparatively small set of cues or inputs. Using human language prompts as input, generative AI (artificial intelligence) can generate content using LLMs.
Key Reasons: Why LLMs Matter
LLMs are transforming the way businesses work and interact with technology. Let's see some of the key reasons below showing why LLMs are important:
- Versatility: One model can handle multiple tasks like chatbots, writing, coding, and analysis.
- Improved Productivity: LLMs automate repetitive and time-consuming tasks, helping teams work faster and more efficiently.
- Enhanced User Experience: They power smarter virtual assistants, search engines, and customer support systems with more natural interactions.
- Content Generation at Scale: Businesses can create blogs, emails, reports, and more with minimal effort.
Types of LLMs
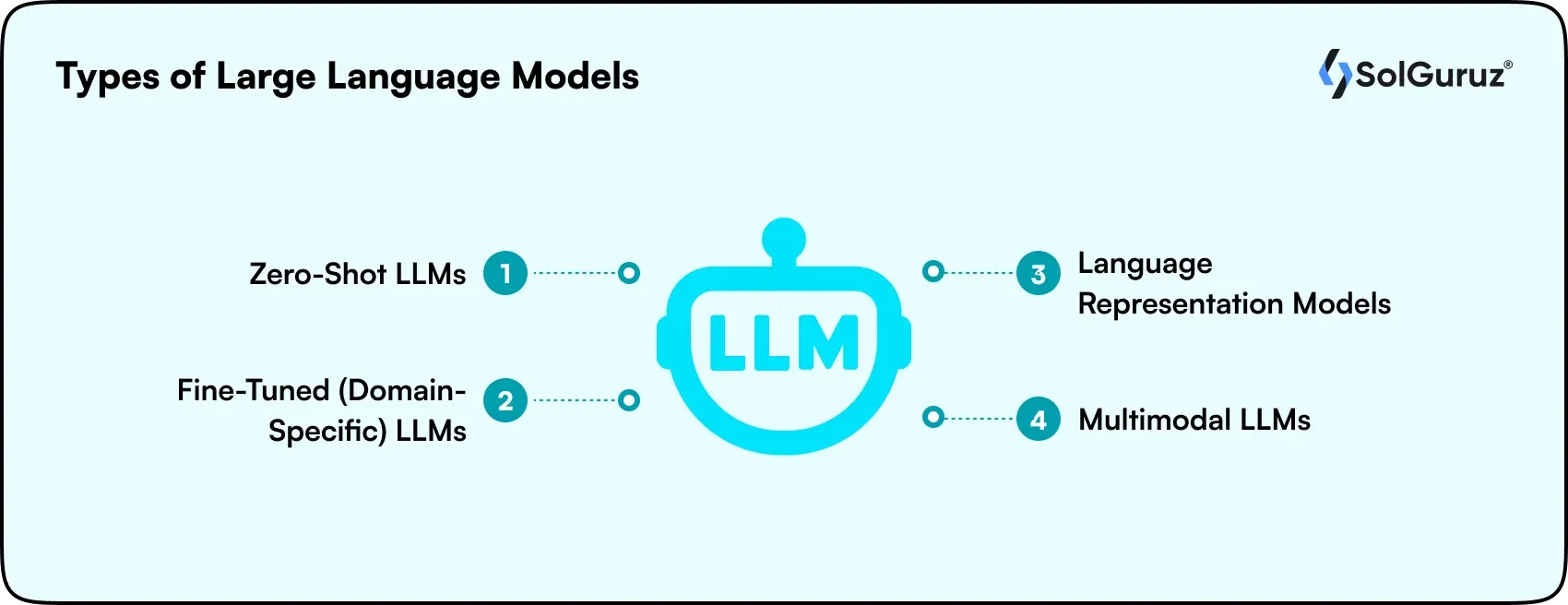
Based on how the LLMs are trained, they are classified into four categories.
1. Zero-shot LLM
Standard LLMs trained on generic data to yield results that are reasonably accurate for typical use situations are known as zero-shot models. These models can be used right away and don't require any further training.
2. Domain-specific or Fine-tuned LLM
Fine-tuned models improve upon the first zero-shot model's efficacy by undergoing extra training. One such is OpenAI Codex, which is widely used as an auto-completion programming tool for GPT-3-based applications. Another name for this is specialized LLMs.
3. Language representation LLM
Models for language representation make use of transformers, the structural cornerstone of generative artificial intelligence, and deep learning methods. These models enable the translation of languages into different media, including written text, and are well-suited for problems involving natural language processing.
4. Multimodal LLM
These LLMs can process both text and images, which sets them apart from their predecessors, who were mainly made for text creation. As an illustration, consider GPT-4V, a more current multimodal version of the model that can produce and interpret content in several modalities.
Challenges of LLM
The different challenges faced while working with LLMs can be -
Inability to Produce Factually Correct Data
Making sure the content they provide is correct and dependable is one of the main challenges. While LLMs are capable of producing writing that is factually incorrect or deceptive.
Security
User-facing apps built on top of LLMs are as vulnerable to security flaws as any other program. Malicious inputs can also be used to alter LLMs such that they give forth responses that are safer or more morally dubious than others. Last but not least, one of the security issues with LLMs is that users may upload private, secure material into them to boost their own productivity. However, LLMs are not meant to be safe havens; in response to inquiries from other users, they may reveal private information because they use the inputs they get to train their models better.
Hallucinations
However, the accuracy of the information provided by LLMs is only as good as the data they consume. They will respond to user inquiries with misleading information if they are given erroneous information. LLMs can also "hallucinate" occasionally, fabricating facts when they are unable to provide a precise response. For instance, ChatGPT was questioned about Tesla's most recent financial quarter by the 2022 news outlet Fast Company. Although ChatGPT responded with a comprehensible news piece, a large portion of the information was made up.
Benefits of LLM
The immense potential of LLMs has multiple advantages.
1. Smart Text Generation or Translation
LLMs are brilliant with words. They may also produce writing that is stylistically akin to that of a specific author or genre. If you train the LLM with Shakespeare and on prompting it will generate a Shakespeare-style poem to delight you.
LLMs are trained in different languages. They are helpful in language translation.
2. Data Generation Capacity
One method of addressing this shortcoming in LLMs is using conversational AI to converse with the model with a trustworthy data source, like a business website. This enables the generative properties of a large language model to generate a variety of helpful content for a virtual agent, such as training data and replies that are consistent with the brand identity.
3. Advanced NLP Skills
AI systems that use natural language processing are better able to comprehend written and spoken language, similar to humans. Prior to LLM, businesses trained machines to comprehend human texts using a variety of machine-learning algorithms. However, the introduction of LLMs such as GPT-3.5 has simplified the procedure. It has improved the speed and accuracy with which AI-powered devices can now comprehend human texts. BARD and ChatGPT are the best instances of it.
4. Enhanced Efficiency
Owing to the NLP technique, LLMs comprehend human language very well; they are ideal for labor-intensive or repetitive jobs. Professionals or organizations can reduce human effort by using LLMs to automate data processing and repetitive tasks. One of the reasons LLMs are so essential in businesses is that they may boost productivity by automating activities.
Use cases of LLM
LLMs have different applications in various fields.
1. Text generation
The ability to create language in response to cues by producing emails, blog posts, or other mid-to-long form content that can be polished and refined. RAG, or retrieval-augmented generation, is a prime example.
2. Content summarization
Condense lengthy articles, news items, research studies, company records, and even client biographies into comprehensive texts with lengths appropriate for the output format.
3. Code generation in Software Development
It helps developers create programs, detect bugs in the code, and even "translate" between different programming languages to locate security flaws.
4. Sentiment analysis
Examine text to ascertain the tone of the consumer to comprehend large-scale customer feedback and support brand reputation management.
The advent of large language models capable of producing text and answering inquiries, such as ChatGPT, Claude 2, and Llama 2, presents intriguing future developments. Their ability to generate human-like text will be refined with time and training.
5. Conversational AI and Chatbots
LLMs power intelligent chatbots and virtual assistants that can answer questions, handle customer support, and provide personalized responses in real time.
Examples include ChatGPT, Claude, and Llama 2.
Real-World Examples of LLMs
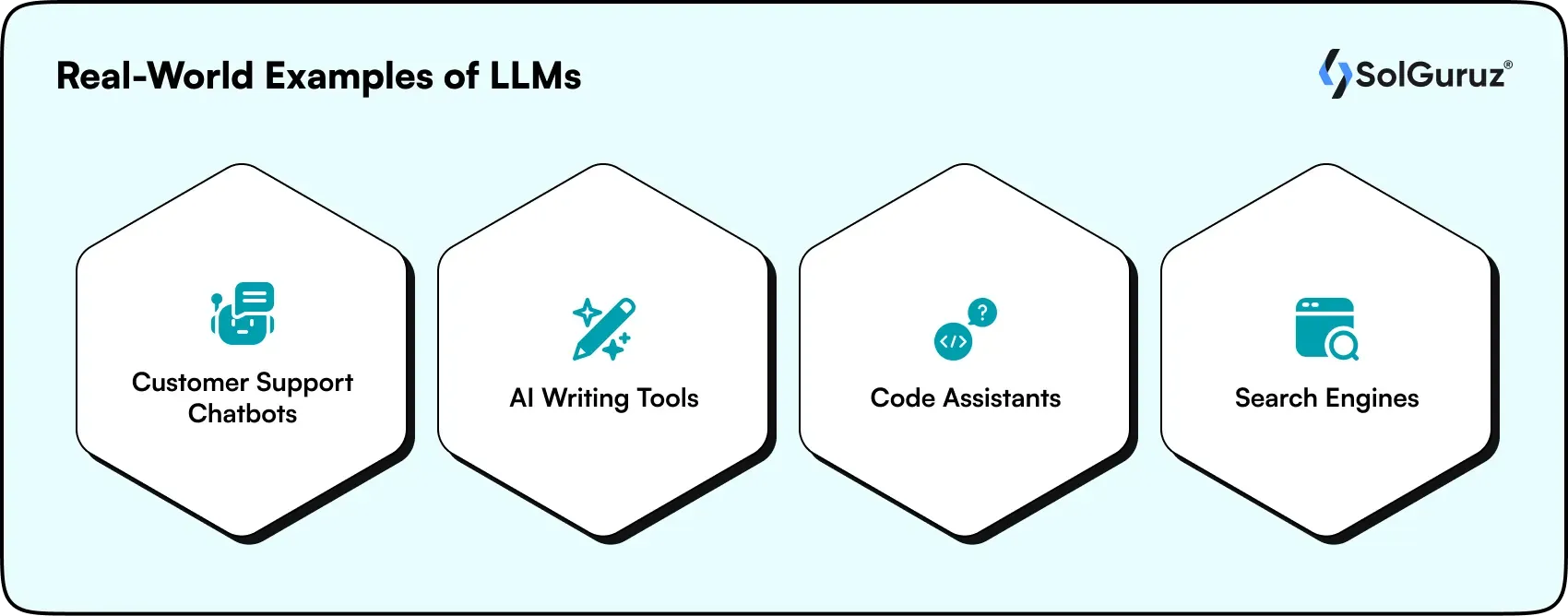
Large language models are not just theoretical; they are actively powering tools and services across industries. Here are some real-world applications where LLMs make a tangible impact:
1. Customer Support Chatbots
LLMs power intelligent chatbots that can automate customer queries, provide personalized responses, and operate 24/7 without human intervention. Unlike rule-based bots, these AI-driven assistants understand context, answer complex questions, and improve customer satisfaction over time.
Example: ChatGPT and Claude are widely integrated into customer service platforms to reduce support costs and response times.
Recommended read on: Top Use Cases of Generative AI In The Real Estate Industry
2. AI Writing Tools
Marketers, content creators, and businesses rely on LLMs to generate high-quality content quickly. From drafting emails and blog posts to creating product descriptions, LLMs accelerate content production while maintaining brand voice and consistency.
Example: Jasper AI and Writesonic use LLMs to assist marketing teams in creating scalable, engaging content.
3. Code Assistants
Developers benefit from LLMs that write, debug, and optimize code, saving hours of manual work. These models can even translate code between programming languages or suggest improvements based on best practices.
Example: GitHub Copilot and OpenAI Codex are LLM-powered tools helping developers streamline software development and reduce errors.
4. Search Engines
Modern search engines leverage LLMs to understand user intent better and provide more accurate, context-aware results. LLMs improve the relevance of answers, summarize content, and enable features like conversational search.
Example: Google Bard and Microsoft Bing Chat enhance search experiences using advanced LLM reasoning and summarization.
Future of Large Language Models
Large language models are evolving rapidly, and their future promises more capabilities, broader adoption, and deeper integration into business processes. Here’s what we can expect in the coming years:
1. Multimodal AI Growth
Future LLMs will not be limited to text, they will understand and generate multiple types of content, including images, audio, and video. This opens up applications like visual question answering, AI-powered design tools, and interactive multimedia assistants.
Example: GPT-4V and Google Gemini are early examples of multimodal models combining text and visual understanding, enabling richer user experiences.
2. Better Reasoning
Next-generation LLMs will have enhanced logical and analytical capabilities, allowing them to solve more complex problems, perform multi-step reasoning, and offer accurate decision-making support. Businesses will be able to rely on AI not just for content, but also for insights and predictions.
Example: Advanced LLMs could help analysts summarize research papers, provide actionable business recommendations, or optimize workflows automatically.
3. Enterprise Adoption
More companies across industries will integrate LLMs into internal systems and customer-facing applications. From automating HR and IT support to improving customer service, LLMs will become a core part of enterprise AI strategies.
Example: Large organizations are already experimenting with AI assistants that generate reports, draft emails, or monitor internal data trends in real time.
4. Regulation & Ethics
As LLM adoption grows, there will be increased focus on governance, fairness, and responsible AI use. Future models will need to comply with data privacy regulations, minimize bias, and provide transparent outputs to maintain user trust.
Example: Regulatory frameworks like the EU AI Act and industry-specific guidelines will shape how LLMs are deployed in sensitive sectors like finance, healthcare, and legal services.
In short, the future of LLMs is multimodal, smarter, enterprise-ready, and ethically guided, transforming how businesses operate, interact with users, and scale AI initiatives. Companies aiming to leverage these advancements should consider hiring AI/ML developers to build customized, efficient, and compliant solutions.
FAQs
1. What is a large language model in simple terms?
A large language model (LLM) is an AI system trained to understand, process, and generate human-like text. It uses deep learning and vast datasets to answer questions, summarize content, translate languages, write content, and assist with decision-making.
2. How do large language models work?
LLMs work by breaking text into tokens, converting them into numerical embeddings, and using transformer architectures to process context. They predict the next word or sentence, token by token, to generate meaningful, human-like responses.
3. What are some real-world examples of LLMs?
LLMs are used in customer support chatbots (ChatGPT, Claude), AI writing tools (Jasper AI, Writesonic), code assistants (GitHub Copilot, OpenAI Codex), and search engines (Google Bard, Microsoft Bing Chat).
4. What are the limitations of large language models?
LLMs can hallucinate information, sometimes generating incorrect or misleading outputs. They may also reflect bias in training data, have high computational costs, and pose data privacy risks if not used responsibly. Proper monitoring and fine-tuning are essential.
5. What is the difference between LLMs and generative AI?
LLMs are a subset of generative AI specifically focused on text-based tasks, such as content generation, summarization, and NLP. Generative AI, in contrast, can create text, images, audio, video, and code, making it broader in scope for multi-format content creation.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

