Fine Tuning LLMs in [2026]: Methods, Tools, and Best Practices
This blog explores how to fine-tune LLMs in 2026 using methods like LoRA, QLoRA, and RLHF. It covers when to use fine-tuning, key tools, costs, and real-world use cases. You’ll also learn a step-by-step process to build and deploy production-ready models.
![Fine Tuning LLMs in [2026]: Methods, Tools, and Best Practices](https://strapi.solz.me/uploads/fine_tuning_llms_6faf5f2430.svg)
Summarise with AI
Short on time? Let AI do the work. Get the key points.
Large language models like GPT-4, LLaMA 3, Mistral, and Gemini are powerful, but they are general-purpose tools. For production-grade AI applications that need domain expertise, brand consistency, or specialized task accuracy, fine-tuning is the answer.
In this complete guide, you will learn exactly what fine-tuning LLM is, when to use it, how it works, which methods to choose, and how to implement it step by step with real code examples, tool comparisons, and cost breakdowns.
What is Fine-Tuning LLMs?
Fine-tuning a large language model (LLM) means continuing the training of a pre-trained model on a smaller, targeted dataset to improve its performance for a specific task or domain.
A base LLM like LLaMA 3 or Mistral 7B is trained on trillions of tokens from the internet. It learns general language patterns but does not know your company's writing style, your product's technical specifications, or how medical records in your EHR system are structured.
Fine-tuning bridges that gap. Instead of building a model from scratch, which costs millions of dollars, you take an existing model and adapt it using your own data. The result is a model that behaves like a specialist, not a generalist.
Why Fine-Tuning Is Needed
Think of a base LLM as a very smart general graduate who has read millions of books. They understand many topics, but they are not yet trained for your specific job.
Fine-tuning is like giving that graduate specialized job training.
After fine-tuning:
- The model answers using your domain vocabulary
- It follows your business rules
- It produces responses in your preferred format or tone
So instead of being a general assistant, it becomes a domain expert assistant.
Fine-Tuning vs. Prompt Engineering vs. RAG
To adapt large language models for real-world applications, developers typically rely on three main approaches: prompt engineering, retrieval-augmented generation (RAG), and fine-tuning. Each method customizes how the model behaves, but they differ in how they provide knowledge, control responses, and handle specialized tasks. The table below compares these approaches.
| Approach | How It Works | Best For | Cost |
| Prompt Engineering | Guide model behavior via instructions | Quick iteration, general tasks | Near zero |
| RAG (Retrieval-Augmented Generation) | Inject live data into context at query time | Dynamic knowledge, large databases | Low–Medium |
| Fine Tuning | Update model weights on domain-specific data | Specialized tasks, consistent behavior | Medium–High |
| Training From Scratch | Build a model on raw data from zero | Fully custom requirements | Very High |
In practice, most AI systems combine these techniques rather than relying on just one. For example, a company may use RAG for accessing updated knowledge, prompt engineering for task instructions, and fine-tuning for consistent domain behavior to build a reliable AI application.
When Should You Fine-Tune an LLM?
Fine-tuning is not always the right choice. Here is a clear decision guide based on your use case:
Fine-Tune When:
- Prompt engineering consistently fails to achieve the required accuracy or output format.
- You need the model to learn a specific writing style, tone, or domain vocabulary that cannot be described in a prompt.
- Your task requires high-volume, low-latency inference, and you cannot afford large context windows for every request.
- You work in a regulated domain (healthcare, legal, finance) where behavior must be predictable and auditable.
- You want to reduce hallucinations on specialized topics by grounding the model in verified domain data.
Skip Fine-Tuning When:
- Your requirements change frequently, but fine-tuned models do not update dynamically.
- You only need general-purpose text generation, summarization, or Q&A on publicly available knowledge.
- RAG (Retrieval-Augmented Generation) can inject the right information at runtime with sufficient accuracy.
- You have fewer than a few hundred high-quality training examples, the model may overfit.
The LLMs Lifecycle and Where Fine-Tuning Fits
Understanding fine-tuning requires understanding where it lives in the LLM development lifecycle:
1. Vision & Scope
Start by defining the goal of the AI system. Decide whether you need a general-purpose assistant or a task-specific model, and clearly outline success criteria such as accuracy, response format, or latency.
2. Model Selection
Choose an appropriate base model based on factors like model size, licensing, cost, and task suitability. Popular choices include LLaMA 3, Mistral 7B, Gemini, or GPT-4o.
3. Alignment & Adjustment (Fine-Tuning Stage)
This is where fine-tuning happens. The selected base model is adapted using domain-specific data so it better understands your terminology, workflows, and expected output format.
4. Evaluation & Iteration
Test the model using task-specific benchmarks and real-world examples. Measure performance, identify errors, and refine the model through additional data or training until quality targets are met.
5. Deployment
Once the model performs reliably, prepare it for production. This includes optimization techniques such as quantization, scalable model serving, and monitoring systems to maintain performance over time.
In simple terms, Fine-tuning sits in the alignment stage of the LLM lifecycle, where a general model is adapted into a domain-specific AI system.
Fine-Tuning LLM Methods: A Complete Comparison
Not all fine-tuning is equal. The method you choose determines your GPU requirements, cost, training time, and the quality of the final model. Here are the most important methods in 2026:
1. Supervised Fine-Tuning (SFT)
The most common fine-tuning approach. You train the model on labeled input-output pairs, typically prompt-response pairs where the correct output is already known.
- Best for: Instruction-following, Q&A, classification, summarization
- Data required: 500–10,000+ labeled examples, depending on task complexity
- Tools: Hugging Face TRL, Axolotl, OpenAI fine-tuning API
2. Parameter-Efficient Fine-Tuning (PEFT); LoRA & QLoRA
LoRA (Low-Rank Adaptation) is the most popular PEFT technique. Instead of updating all model weights, LoRA injects small trainable matrices into the model's attention layers. You only train a fraction of the parameters, typically 0.1–1%, while keeping the original weights frozen.
QLoRA combines LoRA with 4-bit quantization, enabling fine-tuning of 65B+ parameter models on a single consumer GPU (e.g., RTX 4090 or even a single A100).
- Best for: Resource-constrained environments, teams without large GPU clusters
- Memory savings: Up to 65% reduction compared to full fine-tuning
- Tools: Hugging Face PEFT, Unsloth (2–5× faster LoRA training), bitsandbytes
3. RLHF (Reinforcement Learning from Human Feedback)
RLHF is the method used to make models like ChatGPT behave helpfully and safely. It involves three stages: supervised fine-tuning, training a reward model from human preference data, and using PPO (Proximal Policy Optimization) to maximize reward.
- Best for: Aligning models to human preferences, safety-critical applications
- Data required: Large volumes of human preference comparisons (A vs. B rankings)
- Tools: TRL (Transformer Reinforcement Learning), DeepSpeed
4. DPO (Direct Preference Optimization)
DPO is a simpler alternative to full RLHF that removes the need for a separate reward model. It directly optimizes the language model on preference data, making it significantly cheaper and easier to implement.
- Best for: Teams that want alignment results without the complexity of RLHF
- Tools: Hugging Face TRL (DPO Trainer), Axolotl
5. Full Fine-Tuning
All model weights are updated during training. Produces the strongest results but requires substantial computing. Typically used for proprietary foundation models with dedicated infrastructure.
- Best for: Large organizations with GPU clusters, maximum performance requirements
- Tools: DeepSpeed, FSDP (Fully Sharded Data Parallel), Megatron-LM
| Method | GPU Requirement | Performance | Best Use Case |
SFT (Full)
| High (A100 cluster) | Excellent | Max accuracy, enterprise |
| LoRA | Medium (single GPU) | Very Good | Most production use cases |
| QLoRA | Low (consumer GPU) | Good | Resource-constrained |
| RLHF | High | Excellent (aligned) | Safety, helpfulness |
| DPO | Medium | Very Good (aligned) | Preference alignment |
Best Base Models for Fine-Tuning in 2026
Choosing the right base model is as important as the fine-tuning method. Here are the leading options:
| Model | Parameters | Best For | Fine-Tuning Support |
| LLaMA 3.3 (Meta) | 8B / 70B | General purpose, instruction following | Excellent -wide community support |
| Mistral 7B / Mixtral | 7B / 56B (MoE) | Fast inference, coding, RAG | Excellent -LoRA/QLoRA native |
| Gemma 2 (Google) | 2B / 9B / 27B | Small device deployment | Strong - optimized for PEFT |
| Phi-3 (Microsoft) | 3.8B / 14B | Edge devices, low cost | Good -small footprint |
| Qwen 2.5 (Alibaba) | 7B–72B | Multilingual, coding | Strong -multilingual tuning |
| GPT-4o (OpenAI) | Proprietary | Max accuracy, enterprise | Via OpenAI fine-tuning API |
How to Fine-Tune an LLM: Step-by-Step Guide
Here is the complete workflow for fine-tuning an LLM using LoRA/QLoRA with Hugging Face and Unsloth, the most practical setup for most teams in 2026.
Step 1: Prepare Your Training Data
The quality of your fine-tuned model is directly determined by the quality of your training data. You need prompt-response pairs formatted consistently.
Example format (Alpaca-style instruction):
{"instruction": "Summarize the following patient note into a clinical summary.", "input": "Patient presented with chest pain and shortness of breath...", "output": "45-year-old male presented with acute chest pain radiating to the left arm..."}
- Minimum viable dataset: 200–500 high-quality examples for narrow tasks
- Recommended dataset size: 1,000–10,000 examples for most production use cases
- Critical: Data quality matters more than data quantity, 500 clean examples beat 5,000 noisy ones
Step 2: Preprocess and Tokenize the Dataset
Before training begins, the dataset must be converted into tokens, which are the numerical representations that language models understand. Raw text cannot be fed directly into a model.
Tokenization splits text into smaller units (tokens) and converts them into IDs based on the model’s vocabulary. This step also ensures that the instruction, input, and output fields are formatted correctly for training.
For instruction-tuned models, the typical approach is to concatenate the instruction and input as the prompt and use the output as the target response.
Example preprocessing step:
dataset = dataset.map
(
lambda x: tokenizer(
x["instruction"] + x["input"],
text_target=x["output"]
)
)
This transformation prepares the dataset for training by converting each example into token IDs that the model can process.
Important considerations:
- Ensure the prompt format matches the base model’s instruction template.
- Set a maximum sequence length (commonly 2048 or 4096 tokens).
- Remove incomplete or malformed examples during preprocessing.
Step 3: Choose Your Base Model and Method
For most teams, the recommended starting point is:
- Model: LLaMA 3.1 8B or Mistral 7B for cost-efficiency; LLaMA 3 70B or similar high-capacity models for maximum performance.
- Method: QLoRA for GPU-constrained environments; LoRA for standard setups
- Tool: Unsloth for 2–5× faster training; Hugging Face TRL for maximum flexibility
Step 4: FineTune with Unsloth (Code Example)
Here is a working fine-tuning script using Unsloth and Hugging Face TRL (Hugging Face TRL (TRL) is a Python library used to train and fine-tune large language models (LLMs) using reinforcement learning and supervised fine-tuning techniques.)
from unsloth import FastLanguageModel
from trl import SFTTrainer
from transformers import TrainingArguments
# Load model with 4-bit quantization (QLoRA)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Meta-Llama-3.1-8B-Instruct",
max_seq_length=2048,
load_in_4bit=True, # QLoRA 4-bit quantization
)
# Apply LoRA adapters
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA rank
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha=16,
lora_dropout=0,
)
Step 5: Evaluate Your Fine-Tuned Model
After training, evaluate performance using both automated and human methods:
- Perplexity score: Lower is better, measures how well the model predicts your validation data
- Task-specific metrics: BLEU/ROUGE for summarization; accuracy for classification; pass@k for coding
- Human evaluation: Domain experts review a sample of outputs for accuracy, tone, and format compliance
- Benchmark comparisons: Compare the fine-tuned model against the base model and the prompt-engineered baseline
Step 6: Deploy and Monitor
- Export the fine-tuned model and LoRA adapters (GGUF or safetensors format)
- Serve with vLLM, Ollama, or managed services (AWS SageMaker, Google Vertex AI, Modal)
- Monitor output quality in production; fine-tuned models can drift if real-world inputs differ significantly from the training distribution.
Top Fine-Tuning LLMs Tools & Frameworks in 2026
Fine-tuning a language model requires the right tools to handle training, data pipelines, and deployment. The table below lists some of the most widely used frameworks and platforms for LLM fine-tuning.
| Tool | Type | Best For | Cost |
| Hugging Face Transformers + TRL | Framework | Full pipeline, maximum flexibility | Free (open source) |
| Unsloth | Training optimizer | 2–5× faster LoRA/QLoRA training | Free + Pro tier |
| Axolotl | Training config | YAML-driven training, multi-GPU | Free (open source) |
| LLaMA-Factory | UI + config | Beginner-friendly, web UI | Free (open source) |
| OpenAI Fine-Tuning API | Managed service | GPT-3.5 / GPT-4o fine-tuning | Pay per token |
| Vertex AI (Google) | Managed service | Gemini fine-tuning, enterprise scale | Pay per use |
| Amazon SageMaker | Managed service | AWS-native deployment + training | Pay per use |
| Torchtune | Training library | Lightweight PyTorch-native fine-tuning workflows | Free (open source) |
| Lightning AI LitGPT | Training framework | Optimized LLM training with | Free (open source) |
| OpenAI Fine‑Tuning API | Managed service | Fine-tuning GPT models without infrastructure | Pay per token |
| Amazon SageMaker | Managed service | Full ML pipelines and deployment on AWS | Pay per use |
PEFT Deep Dive: LoRA, QLoRA, and Parameter-Efficient Methods
Parameter-Efficient Fine-Tuning (PEFT) has made LLM fine-tuning accessible to teams without access to large GPU clusters. Here is how the main techniques work:
How LoRA Works
Standard fine-tuning updates every parameter in a weight matrix W, which can involve billions of parameters. LoRA (Low-Rank Adaptation) reduces this cost by representing the weight update as the product of two smaller matrices.
Then introduce the formula.
ΔW=A×B\Delta W = A \times BΔW=A×B
Where:
- W = original weight matrix
- ΔW = weight update applied during training
- A, B = low-rank matrices with rank r
Instead of updating the entire matrix, LoRA trains only A and B, which typically represent less than 1% of the model parameters.
LoRA Hyperparameters You Need to Know
| Parameter | What It Controls | Typical Range | Impact |
| r (rank) | Number of trainable parameters in adapters | 4, 8, 16, 32, 64 | Higher = more capacity, more VRAM |
| lora_alpha | Scaling factor for LoRA updates | Usually = r or 2×r | Higher = stronger adapter effect |
| lora_dropout | Regularization to prevent overfitting | 0 to 0.1 | Small datasets benefit from 0.05 |
| target_modules | Which layers to apply LoRA to | q_proj, v_proj (min); all attn layers (best) | More layers = better quality, more VRAM |
QLoRA: Fine-Tuning 70B Models on a Single GPU
QLoRA combines LoRA with NF4 (Normal Float 4-bit) quantization of the frozen base model weights. The base model is loaded in 4 bits, dramatically reducing VRAM requirements. LoRA adapters are still trained in full 16-bit precision, preserving quality.
- LLaMA 3.1 8B with QLoRA: ~6GB VRAM (fits on RTX 3080)
- LLaMA 3 70B with QLoRA: ~48GB VRAM (fits on 2×A100 40GB or single H100)
- Full fine-tuning of 70B: 500GB+ VRAM - impractical for most teams
Real-World LLM Fine-Tuning Use Cases
Fine-tuning LLM is widely used across industries where domain knowledge, accuracy, and consistent output formats are critical. The following examples show how organizations apply fine-tuned models to solve real-world problems and improve operational efficiency.
1. Healthcare & Medical AI
Medical teams fine-tune LLMs to understand clinical language, ICD codes, and HIPAA-compliant documentation styles. A GPT-4 base model fine-tuned on 50,000 de-identified clinical notes can generate structured patient summaries with significantly fewer hallucinations than a prompt-engineered baseline.
- Use case: Automated clinical note summarization
- Model: LLaMA 3.1 70B or Mistral 7B fine-tuned on MIMIC-III
- Key benefit: Consistent output format, reduced hallucination rate on medical terminology
2. Legal & Compliance
Law firms and compliance teams fine-tune models to understand contract language, jurisdiction-specific regulations, and internal precedent databases. This replaces weeks of manual review with accurate, auditable AI-assisted analysis.
- Use case: Contract clause extraction and risk flagging
- Model: GPT-4o fine-tuning API or open-source LLaMA on private contract corpora
3. Customer Support & Chatbots
E-commerce and SaaS companies fine-tune support models on historical ticket data, product documentation, and resolution records. The result is a model that resolves Level 1 tickets accurately without human escalation.
- Use case: Tier-1 support automation
- Reported result: 40–65% ticket deflection on fine-tuned models vs. 15–25% on prompt-engineered GPT-4
4. Code Generation & Developer Tools
Engineering teams fine-tune coding models on their internal codebase, API documentation, and coding standards. This produces a code assistant that suggests implementations matching the team's actual patterns and libraries -not generic StackOverflow-style answers.
- Use case: Internal code completion and code review assistance
- Model: DeepSeek Coder, CodeLLaMA, or Starcoder fine-tuned on internal repos
5. Financial Services
Banks and fintech firms fine-tune models to understand financial reporting language, risk terminology, and regulatory frameworks like Basel III or IFRS 17. Fine-tuned models can draft XBRL-tagged financial reports from structured inputs with minimal manual correction.
- Use case: Regulatory report drafting, earnings call analysis
- Key requirement: Models must never hallucinate financial figures - fine-tuning reduces this risk significantly
Fine-Tuning LLMs Cost Breakdown
One of the most common questions developers ask is: how much does it actually cost to fine-tune an LLM? The answer depends on model size, training hours, and infrastructure choice.
| Scenario | Model & Method | Infra | Estimated Cost |
| Individual developer | Mistral 7B (QLoRA) | Google Colab Pro / single A100 | $5 – $30 |
| Small team, narrow task | LLaMA 3.1 8B (LoRA) | 2× A100 80GB (Lambda Labs) | $50 – $200 |
| Production fine-tune | LLaMA 3.3 70B (QLoRA) | 4× A100 80GB cloud run | $200 – $800 |
| Enterprise scale | LLaMA 3.3 70B (Full fine-tune) | Multi-node H100 cluster | $5,000 – $50,000+ |
| Managed API (GPT-4o) | GPT-4o (SFT via API) | OpenAI fine-tuning API | $0.008/1K tokens training |
Common Fine-Tuning LLMs Mistakes (And How to Avoid Them)
Fine-tuning can significantly improve model performance, but common mistakes in data preparation, evaluation, or deployment can reduce its effectiveness. The following pitfalls highlight what teams often get wrong and how to avoid them when fine-tuning LLMs.
1. Mistake: Using Too Little Data
Training with fewer than 200 examples often leads to overfitting, where the model memorizes the dataset instead of learning general patterns.
- How to Avoid It: Use at least 500–1,000 diverse, high-quality examples so the model learns patterns that generalize to new inputs.
2. Mistake: Ignoring Data Quality
A fine-tuned model amplifies patterns in its training data, including errors, inconsistencies, or formatting issues.
- How to Avoid It: Prioritize clean, consistent, and well-structured datasets. Well-curated data is often more valuable than simply increasing the amount of data.
3. Mistake: Not Establishing a Baseline
Teams sometimes jump directly into fine-tuning without evaluating simpler alternatives.
- How to Avoid It: First, test the base model and a prompt-engineered version. Only proceed with fine-tuning if it provides a clear improvement in accuracy or output consistency.
4. Mistake: Catastrophic Forgetting
Fine-tuning on narrow or highly specialized datasets can cause the model to lose its broader language capabilities.
- How to Avoid It: Use techniques like LoRA or mix in general instruction data during training to preserve the model’s original knowledge.
5. Mistake: Skipping Proper Evaluation
Relying only on metrics like perplexity does not always reflect real-world performance.
- How to Avoid It: Define task-specific evaluation metrics and have domain experts review a sample of outputs to verify accuracy and reliability.
6. Mistake: Deploying Without Monitoring
Fine-tuned models may perform well initially but degrade when input patterns change.
- How to Avoid It: Modern AI-powered applications require ongoing evaluation to maintain quality and detect model drift early.
How to Choose the Right Fine-Tuning Approach for Your Team
Choosing the right fine-tuning approach depends on your team size, technical expertise, infrastructure, and budget. Many organizations work with experienced AI/ML developers to identify the most efficient training strategy and tools for their specific use case. The table below outlines common scenarios and the recommended methods and tools that best fit each situation.
| Your Situation | Recommended Approach | Recommended Tool |
| Individual developer, learning fine-tuning | QLoRA on 7B model | Unsloth + Google Colab |
| Small team, narrow classification, on or Q&A task | LoRA SFT on 7B–13B | Axolotl or LLaMA-Factory |
| Medium team, customer support automation | LoRA SFT + DPO for alignment | HuggingFace TRL + Unsloth |
| Enterprise, regulated domain (healthcare/finance) | Full fine-tune or LoRA at scale | AWS SageMaker or Vertex AI |
| Team using the OpenAI stack | GPT-4o fine-tuning | OpenAI Fine-Tuning API |
| Start with a limited budget | QLoRA on Mistral 7B | Unsloth + RunPod GPU rental |
The Future of Fine-Tuning LLM in 2026 and Beyond

As large language models continue to evolve, fine-tuning techniques are rapidly improving in terms of speed, cost efficiency, and scalability. The following trends highlight how fine-tuning practices are expected to develop in the coming years.
1. Fine-Tuning Gets Faster and Cheaper
Unsloth's 2–5× speed improvements are just the beginning. Emerging techniques like GaLore, Flora, and spectrum fine-tuning are pushing parameter efficiency even further. By 2027, fine-tuning a production-grade 7B model on 1,000 examples will likely take under 10 minutes on a standard cloud GPU.
2. Synthetic Data Generation Removes Data Bottlenecks
Generating fine-tuning data with frontier models like GPT-4o and Claude 3.5 is now a standard practice. Teams generate thousands of high-quality training examples in hours rather than months. This removes the data collection bottleneck that previously made fine-tuning impractical for smaller teams.
3. Continuous Fine-Tuning in Production
Static fine-tuned models deployed once and left unchanged are giving way to systems that continuously fine-tune on production feedback. Reward models automatically flag low-quality outputs; approved corrections are batched into new fine-tuning runs. The model improves continuously without manual intervention.
4. Alignment and Safety Fine-Tuning Becomes Standard
With AI regulation accelerating globally, EU AI Act enforcement began in August 2026; organizations must demonstrate that their fine-tuned models behave safely and predictably. DPO and RLHF-based alignment fine-tuning, once limited to frontier labs, is now accessible to enterprise teams as tooling matures.
How SolGuruz Implements Fine-Tuning LLM for Clients
At SolGuruz, we have helped companies across healthcare, fintech, and enterprise SaaS implement production-grade LLM fine-tuning solutions. Our approach follows a structured methodology:
1. Discovery & Data Audit
We start by analyzing your existing data assets and identifying the most valuable fine-tuning opportunities. During this phase, we also establish baseline performance benchmarks to measure improvements after training.
2. Data Pipeline Design
Next, we design scalable data pipelines for collecting, cleaning, and formatting training data. When labeled data is limited, we also apply techniques like synthetic data generation and augmentation to improve training quality.
3. Model Selection & Method
Based on your performance requirements, infrastructure constraints, and budget, we select the most suitable base model and fine-tuning method to ensure optimal results.
4. Training, Evaluation & Iteration
We run controlled fine-tuning experiments and evaluate results using domain-specific metrics. The model is iteratively improved until it meets defined accuracy and reliability thresholds.
5. Production Deployment & Monitoring
Finally, we deploy the fine-tuned model with scalable inference infrastructure and implement monitoring systems to detect performance drift and maintain consistent output quality in production.
Need help implementing LLM solutions for your business? Hire AI app developer experts at SolGuruz to build and deploy custom AI-powered applications tailored to your domain
Our clients typically achieve 40–70% improvement in task-specific accuracy compared to prompt-engineered baselines with production deployments running reliably at scale.
Wrapping Up
Fine-tuning LLM has moved from a research technique to a production-critical capability in 2026. With parameter-efficient methods like LoRA and QLoRA, and tools like Unsloth and Hugging Face TRL, teams of any size can now build specialized AI models that outperform general-purpose LLMs on domain-specific tasks.
The key principles to remember:
- Start with the simplest approach that works: prompt engineering first, RAG second, fine-tuning third.
- Data quality drives model quality. Invest in clean, diverse, correctly-formatted training data.
- Use PEFT methods (LoRA, QLoRA) unless you have specific reasons to do full fine-tuning.
- Measure everything: baselines, task-specific metrics, and production quality over time.
- Fine-tuning is iterative;e the first version is rarely the final version.
FAQs
1. Is fine-tuning the same as retraining?
No. Retraining (or training from scratch) starts with random weights and requires massive computing. Fine-tuning starts from an already-trained model and continues training it on new data, dramatically cheaper and faster.
2. Can I fine-tune a model on my own data without sharing it?
Yes. Open-source models (LLaMA 3, Mistral, Gemma) can be fine-tuned entirely on your own infrastructure with your private data. Managed APIs like OpenAI may process your data server-side; review their data usage policies before sending sensitive data.
3. How long does fine-tuning take?
With Unsloth and QLoRA on a single A100 GPU: 500 examples fine-tune in 15–30 minutes. 5,000 examples take 2–4 hours. Full fine-tuning at scale (70B model, 100K examples) can take days on a multi-GPU cluster.
4. What's the difference between LoRA and full fine-tuning?
Full fine-tuning updates all model weights to maximum quality, maximum compute. LoRA only trains small adapter matrices injected into the model - 90–99% fewer trainable parameters, similar quality for most tasks. LoRA is recommended for almost all production use cases.
5. What is the difference between fine-tuning and training from scratch?
Training from scratch requires building a model on billions of tokens of raw text, costing millions of dollars and months of compute. Fine-tuning starts with an already-trained model and continues training it on a small, targeted dataset. Most teams should never train from scratch; fine-tuning achieves 80–95% of the quality at 1–5% of the cost.
6. How much data do I need to fine-tune an LLM?
For narrow tasks (specific output format, single domain), 200–500 high-quality examples can be sufficient. For broader domain adaptation or instruction-following improvement, 1,000–10,000+ examples are recommended. Quality consistently beats quantity in fine-tuning data.
7. Can I fine-tune an LLM locally?
Yes. With QLoRA and tools like Unsloth or Ollama, you can fine-tune models up to 13B parameters on a single consumer GPU with 24GB VRAM (e.g., RTX 4090). For larger models, cloud GPU rentals (Lambda Labs, RunPod) are cost-effective at $1–$3/hour.
8. Does fine-tuning an LLM make it forget what it already knows?
This is called catastrophic forgetting. Full fine-tuning on narrow data can degrade general capabilities. LoRA mitigates this by keeping base model weights frozen. You can also include a small percentage of general instruction data in your training mix to preserve broad capabilities.
Looking for an AI Development Partner?
SolGuruz helps you build reliable, production-ready AI solutions - from LLM apps and AI agents to end-to-end AI product development.

Strict NDA

Trusted by Startups & Enterprises Worldwide

Flexible Engagement Models

1 Week Risk-Free Trial
Next-Gen AI Development Services
As a leading AI development agency, we build intelligent, scalable solutions - from LLM apps to AI agents and automation workflows. Our AI development services help modern businesses upgrade their products, streamline operations, and launch powerful AI-driven experiences faster.








Why SolGuruz Is the #1 AI Development Company?
Most teams can build AI features. We build AI that moves your business forward.
As a trusted AI development agency, we don’t just offer AI software development services. We combine strategy, engineering, and product thinking to deliver solutions that are practical, scalable, and aligned with real business outcomes - not just hype.
Why Global Brands Choose SolGuruz as Their AI Development Company:
Business - First Approach
We always begin by understanding what you're really trying to achieve, like automating any mundane task, improving decision-making processes, or personalizing user experiences. Whatever it is, we will make sure to build an AI solution that strictly meets your business goals and not just any latest technology.
Custom AI Development (No Templates, No Generic Models)
Every business is unique, and so is its workflow, data, and challenges. That's why we don't believe in using templates or ready-made models. Instead, what we do is design your AI solution from scratch, specifically for your needs, so that you get exactly what works for your business.
Fast Delivery With Proven Engineering Processes
We know your time matters. That's why we follow a solid, well-tested delivery process. Our developers follow AI-Assisted Software Development principles to move fast and stay flexible to make changes. Moreover, we always keep you posted at every step of the AI software development process.
Senior AI Engineers & Product Experts
When you work with us, you're teaming up with experienced AI engineers, data scientists, and designers who've delivered real results across industries. And they are not just technically strong but actually know how to turn complex ideas into working products that are clean, efficient, and user-friendly.
Transparent, Reliable, and Easy Collaboration
From day one, we keep clear expectations on timelines, take feedback positively, and share regular check-ins. So that you'll always know how we are progressing and how it's going.
From Our Portfolio
AI Projects We Have Shipped to Production
SolGuruz has shipped 102+ products across 14 industries. See how SolGuruz built production AI applications - LLM-powered clinical documentation, AI travel planning, healthcare staffing intelligence, and AI journaling - using GPT-4, Claude, and custom ML models at real-world scale.

AI Clinical Notes Platform That Turns 2-Hour Documentation Into One Click
NoteCliniq transforms clinical conversations into HIPAA-compliant SOAP notes in seconds, eliminating 2+ hours of manual documentation daily for busy clinicians.
Key Outcomes
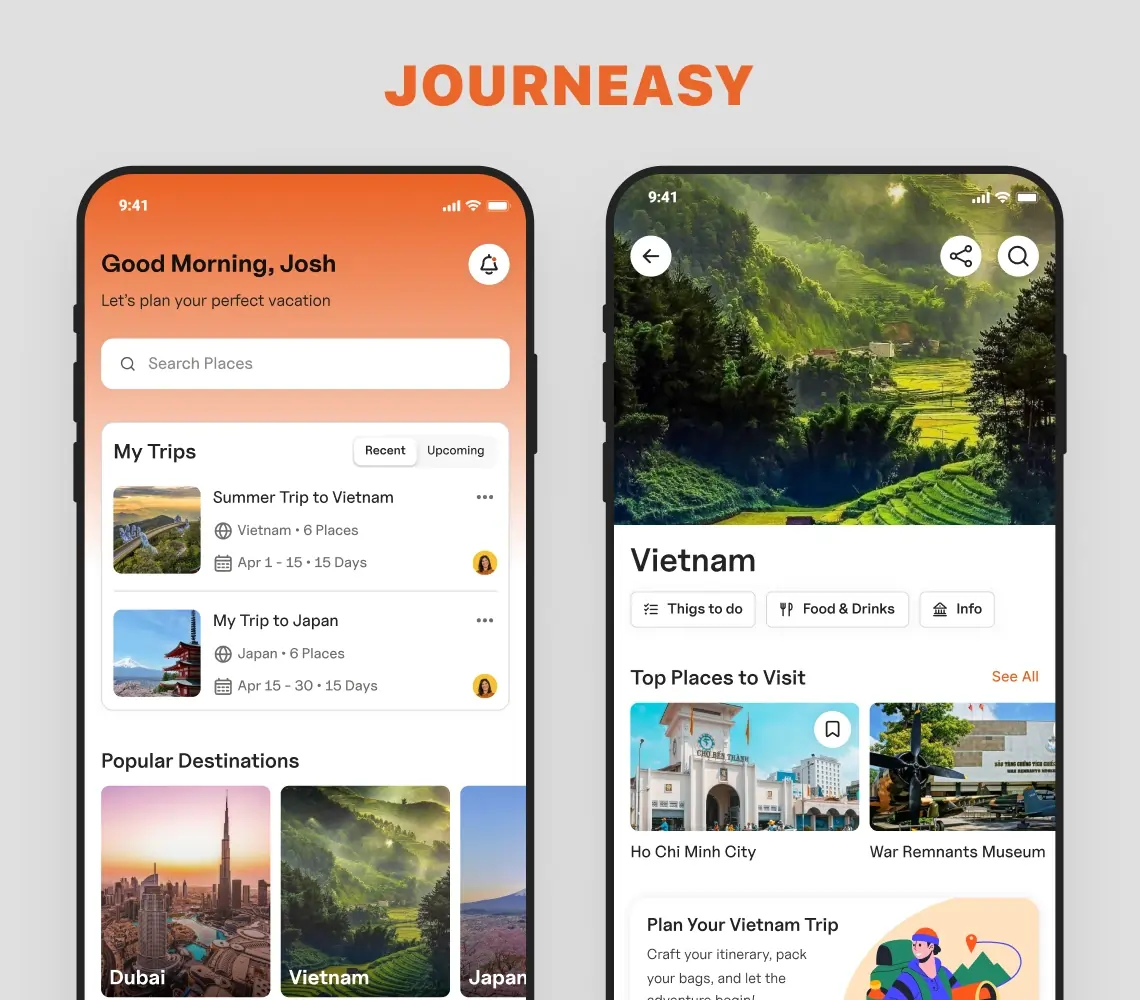
AI-Powered Trip Planner App Solution
Explore how SolGuruz created an AI-powered trip planner app. It is an exclusive AI vacation planner that helps with finding hotels, cabs, places, and complete itineraries.
Key Outcomes
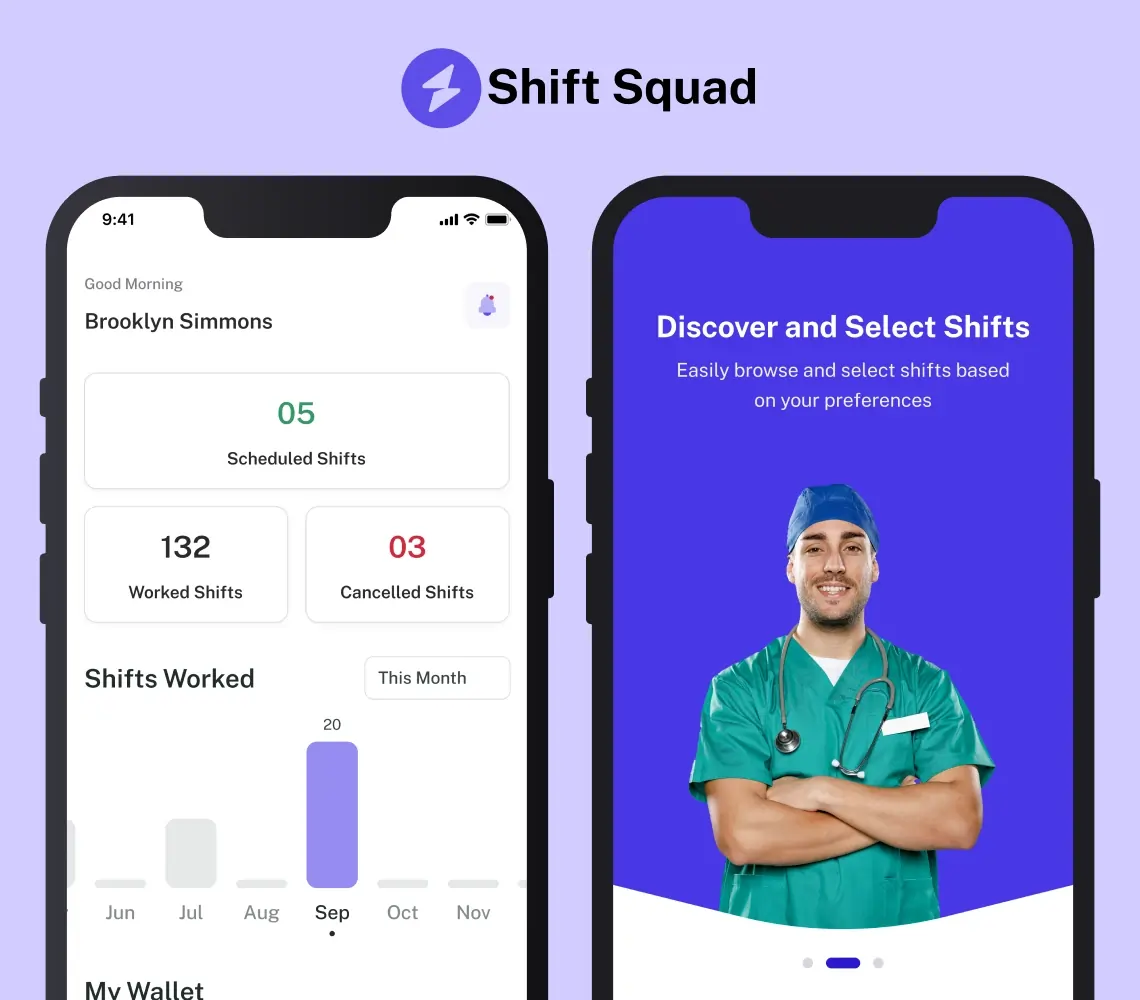
AI-Powered Healthcare Staffing App Solution
Explore our AI-powered healthcare staffing app case study. See how SolGuruz’s expertise transforms nurse staffing challenges into seamless solutions.
Key Outcomes

AI Journaling App Development Solution
Discover with us how we built Dream Story, an AI-powered journaling application that helps manage daily notes by capturing your thoughts and emotions. A one-stop solution for those who love noting down daily summaries!
Key Outcomes
Whether you’re modernizing a legacy system or launching a new AI-powered product, our AI engineers and product team help you design, develop, and deploy solutions that deliver real business value.

